Merge pull request #35 from bmaltais/dev
Add support for --output_name to GUI
This commit is contained in:
commit
f1b595a141
29
README.md
29
README.md
@ -51,6 +51,7 @@ To install simply unzip the directory and place the cudnn_windows folder in the
|
||||
Run the following command to install:
|
||||
|
||||
```
|
||||
.\venv\Scripts\activate
|
||||
python .\tools\cudann_1.8_install.py
|
||||
```
|
||||
|
||||
@ -72,35 +73,43 @@ Once the commands have completed successfully you should be ready to use the new
|
||||
To run the GUI you simply use this command:
|
||||
|
||||
```
|
||||
gui.cmd
|
||||
gui.ps1
|
||||
```
|
||||
|
||||
## Dreambooth
|
||||
|
||||
You can find the dreambooth solution spercific [Dreambooth README](README_dreambooth.md)
|
||||
You can find the dreambooth solution spercific [Dreambooth README](train_db_README.md)
|
||||
|
||||
## Finetune
|
||||
|
||||
You can find the finetune solution spercific [Finetune README](README_finetune.md)
|
||||
You can find the finetune solution spercific [Finetune README](fine_tune_README.md)
|
||||
|
||||
## Train Network
|
||||
|
||||
You can find the train network solution spercific [Train network README](train_network_README.md)
|
||||
|
||||
## LoRA
|
||||
|
||||
You can create LoRA network by running the dedicated GUI with:
|
||||
Training a LoRA currently use the `train_network.py` python code. You can create LoRA network by using the all-in-one `gui.cmd` or by running the dedicated LoRA training GUI with:
|
||||
|
||||
```
|
||||
.\venv\Scripts\activate
|
||||
python lora_gui.py
|
||||
```
|
||||
|
||||
or via the all in one GUI:
|
||||
|
||||
```
|
||||
python kahya_gui.py
|
||||
```
|
||||
|
||||
Once you have created the LoRA network you can generate images via auto1111 by installing the extension found here: https://github.com/kohya-ss/sd-webui-additional-networks
|
||||
|
||||
## Change history
|
||||
|
||||
* 2023/01/10 (v20.1):
|
||||
- Add support for `--output_name` to trainers
|
||||
- Refactor code for easier maintenance
|
||||
* 2023/01/10 (v20.0):
|
||||
- Update code base to match latest kohys_ss code upgrade in https://github.com/kohya-ss/sd-scripts
|
||||
* 2023/01/09 (v19.4.3):
|
||||
- Add vae support to dreambooth GUI
|
||||
- Add gradient_checkpointing, gradient_accumulation_steps, mem_eff_attn, shuffle_caption to finetune GUI
|
||||
- Add gradient_accumulation_steps, mem_eff_attn to dreambooth lora gui
|
||||
* 2023/01/08 (v19.4.2):
|
||||
- Add find/replace option to Basic Caption utility
|
||||
- Add resume training and save_state option to finetune UI
|
||||
|
||||
@ -1,204 +0,0 @@
|
||||
# Kohya_ss Dreambooth
|
||||
|
||||
This repo provide all the required code to run the Dreambooth version found in this note: https://note.com/kohya_ss/n/nee3ed1649fb6
|
||||
|
||||
## Required Dependencies
|
||||
|
||||
Python 3.10.6 and Git:
|
||||
|
||||
- Python 3.10.6: https://www.python.org/ftp/python/3.10.6/python-3.10.6-amd64.exe
|
||||
- git: https://git-scm.com/download/win
|
||||
|
||||
Give unrestricted script access to powershell so venv can work:
|
||||
|
||||
- Open an administrator powershell window
|
||||
- Type `Set-ExecutionPolicy Unrestricted` and answer A
|
||||
- Close admin powershell window
|
||||
|
||||
## Installation
|
||||
|
||||
Open a regular Powershell terminal and type the following inside:
|
||||
|
||||
```powershell
|
||||
git clone https://github.com/bmaltais/kohya_ss.git
|
||||
cd kohya_ss
|
||||
|
||||
python -m venv --system-site-packages venv
|
||||
.\venv\Scripts\activate
|
||||
|
||||
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
|
||||
pip install --upgrade -r requirements.txt
|
||||
pip install -U -I --no-deps https://github.com/C43H66N12O12S2/stable-diffusion-webui/releases/download/f/xformers-0.0.14.dev0-cp310-cp310-win_amd64.whl
|
||||
|
||||
cp .\bitsandbytes_windows\*.dll .\venv\Lib\site-packages\bitsandbytes\
|
||||
cp .\bitsandbytes_windows\cextension.py .\venv\Lib\site-packages\bitsandbytes\cextension.py
|
||||
cp .\bitsandbytes_windows\main.py .\venv\Lib\site-packages\bitsandbytes\cuda_setup\main.py
|
||||
|
||||
accelerate config
|
||||
|
||||
```
|
||||
|
||||
Answers to accelerate config:
|
||||
|
||||
```txt
|
||||
- 0
|
||||
- 0
|
||||
- NO
|
||||
- NO
|
||||
- All
|
||||
- fp16
|
||||
```
|
||||
|
||||
### Optional: CUDNN 8.6
|
||||
|
||||
This step is optional but can improve the learning speed for NVidia 4090 owners...
|
||||
|
||||
Due to the filesize I can't host the DLLs needed for CUDNN 8.6 on Github, I strongly advise you download them for a speed boost in sample generation (almost 50% on 4090) you can download them from here: https://b1.thefileditch.ch/mwxKTEtelILoIbMbruuM.zip
|
||||
|
||||
To install simply unzip the directory and place the cudnn_windows folder in the root of the kohya_diffusers_fine_tuning repo.
|
||||
|
||||
Run the following command to install:
|
||||
|
||||
```
|
||||
python .\tools\cudann_1.8_install.py
|
||||
```
|
||||
|
||||
## Upgrade
|
||||
|
||||
When a new release comes out you can upgrade your repo with the following command:
|
||||
|
||||
```powershell
|
||||
cd kohya_ss
|
||||
git pull
|
||||
.\venv\Scripts\activate
|
||||
pip install --upgrade -r requirements.txt
|
||||
```
|
||||
|
||||
Once the commands have completed successfully you should be ready to use the new version.
|
||||
|
||||
## GUI
|
||||
|
||||
There is now support for GUI based training using gradio. You can start the complete kohya training GUI interface by running:
|
||||
|
||||
```powershell
|
||||
.\venv\Scripts\activate
|
||||
.\kohya_gui.cmd
|
||||
```
|
||||
|
||||
## CLI
|
||||
|
||||
You can find various examples of how to leverage the `train_db.py` in this folder: https://github.com/bmaltais/kohya_ss/tree/master/examples
|
||||
|
||||
## Support
|
||||
|
||||
Drop by the discord server for support: https://discord.com/channels/1041518562487058594/1041518563242020906
|
||||
|
||||
## Quickstart screencast
|
||||
|
||||
You can find a screen cast on how to use the GUI at the following location:
|
||||
|
||||
[](https://www.youtube.com/watch?v=RlvqEKj03WI)
|
||||
|
||||
## Folders configuration
|
||||
|
||||
Refer to the note to understand how to create the folde structure. In short it should look like:
|
||||
|
||||
```
|
||||
<arbitrary folder name>
|
||||
|- <arbitrary class folder name>
|
||||
|- <repeat count>_<class>
|
||||
|- <arbitrary training folder name>
|
||||
|- <repeat count>_<token> <class>
|
||||
```
|
||||
|
||||
Example for `asd dog` where `asd` is the token word and `dog` is the class. In this example the regularization `dog` class images contained in the folder will be repeated only 1 time and the `asd dog` images will be repeated 20 times:
|
||||
|
||||
```
|
||||
my_asd_dog_dreambooth
|
||||
|- reg_dog
|
||||
|- 1_dog
|
||||
`- reg_image_1.png
|
||||
`- reg_image_2.png
|
||||
...
|
||||
`- reg_image_256.png
|
||||
|- train_dog
|
||||
|- 20_asd dog
|
||||
`- dog1.png
|
||||
...
|
||||
`- dog8.png
|
||||
```
|
||||
|
||||
## Support
|
||||
|
||||
Drop by the discord server for support: https://discord.com/channels/1041518562487058594/1041518563242020906
|
||||
|
||||
## Contributors
|
||||
|
||||
- Lord of the universe - cacoe (twitter: @cac0e)
|
||||
|
||||
## Change history
|
||||
|
||||
* 12/19 (v18.5) update:
|
||||
- Create model and log folder when running th dreambooth folder creation utility
|
||||
* 12/19 (v18.4) update:
|
||||
- Add support for shuffle_caption, save_state, resume, prior_loss_weight under "Advanced Configuration" section
|
||||
- Fix issue with open/save config not working properly
|
||||
* 12/19 (v18.3) update:
|
||||
- fix stop encoder training issue
|
||||
* 12/19 (v18.2) update:
|
||||
- Fix file/folder opening behind the browser window
|
||||
- Add WD14 and BLIP captioning to utilities
|
||||
- Improve overall GUI layout
|
||||
* 12/18 (v18.1) update:
|
||||
- Add Stable Diffusion model conversion utility. Make sure to run `pip upgrade -U -r requirements.txt` after updating to this release as this introduce new pip requirements.
|
||||
* 12/17 (v18) update:
|
||||
- Save model as option added to train_db_fixed.py
|
||||
- Save model as option added to GUI
|
||||
- Retire "Model conversion" parameters that was essentially performing the same function as the new `--save_model_as` parameter
|
||||
* 12/17 (v17.2) update:
|
||||
- Adding new dataset balancing utility.
|
||||
* 12/17 (v17.1) update:
|
||||
- Adding GUI for kohya_ss called dreambooth_gui.py
|
||||
- removing support for `--finetuning` as there is now a dedicated python repo for that. `--fine-tuning` is still there behind the scene until kohya_ss remove it in a future code release.
|
||||
- removing cli examples as I will now focus on the GUI for training. People who prefer cli based training can still do that.
|
||||
* 12/13 (v17) update:
|
||||
- Added support for learning to fp16 gradient (experimental function). SD1.x can be trained with 8GB of VRAM. Specify full_fp16 options.
|
||||
* 12/06 (v16) update:
|
||||
- Added support for Diffusers 0.10.2 (use code in Diffusers to learn v-parameterization).
|
||||
- Diffusers also supports safetensors.
|
||||
- Added support for accelerate 0.15.0.
|
||||
* 12/05 (v15) update:
|
||||
- The script has been divided into two parts
|
||||
- Support for SafeTensors format has been added. Install SafeTensors with `pip install safetensors`. The script will automatically detect the format based on the file extension when loading. Use the `--use_safetensors` option if you want to save the model as safetensor.
|
||||
- The vae option has been added to load a VAE model separately.
|
||||
- The log_prefix option has been added to allow adding a custom string to the log directory name before the date and time.
|
||||
* 11/30 (v13) update:
|
||||
- fix training text encoder at specified step (`--stop_text_encoder_training=<step #>`) that was causing both Unet and text encoder training to stop completely at the specified step rather than continue without text encoding training.
|
||||
* 11/29 (v12) update:
|
||||
- stop training text encoder at specified step (`--stop_text_encoder_training=<step #>`)
|
||||
- tqdm smoothing
|
||||
- updated fine tuning script to support SD2.0 768/v
|
||||
* 11/27 (v11) update:
|
||||
- DiffUsers 0.9.0 is required. Update with `pip install --upgrade -r requirements.txt` in the virtual environment.
|
||||
- The way captions are handled in DreamBooth has changed. When a caption file existed, the file's caption was added to the folder caption until v10, but from v11 it is only the file's caption. Please be careful.
|
||||
- Fixed a bug where prior_loss_weight was applied to learning images. Sorry for the inconvenience.
|
||||
- Compatible with Stable Diffusion v2.0. Add the `--v2` option. If you are using `768-v-ema.ckpt` or `stable-diffusion-2` instead of `stable-diffusion-v2-base`, add `--v_parameterization` as well. Learn more about other options.
|
||||
- Added options related to the learning rate scheduler.
|
||||
- You can download and use DiffUsers models directly from Hugging Face. In addition, DiffUsers models can be saved during training.
|
||||
* 11/21 (v10):
|
||||
- Added minimum/maximum resolution specification when using Aspect Ratio Bucketing (min_bucket_reso/max_bucket_reso option).
|
||||
- Added extension specification for caption files (caption_extention).
|
||||
- Added support for images with .webp extension.
|
||||
- Added a function that allows captions to learning images and regularized images.
|
||||
* 11/18 (v9):
|
||||
- Added support for Aspect Ratio Bucketing (enable_bucket option). (--enable_bucket)
|
||||
- Added support for selecting data format (fp16/bf16/float) when saving checkpoint (--save_precision)
|
||||
- Added support for saving learning state (--save_state, --resume)
|
||||
- Added support for logging (--logging_dir)
|
||||
* 11/14 (diffusers_fine_tuning v2):
|
||||
- script name is now fine_tune.py.
|
||||
- Added option to learn Text Encoder --train_text_encoder.
|
||||
- The data format of checkpoint at the time of saving can be specified with the --save_precision option. You can choose float, fp16, and bf16.
|
||||
- Added a --save_state option to save the learning state (optimizer, etc.) in the middle. It can be resumed with the --resume option.
|
||||
* 11/9 (v8): supports Diffusers 0.7.2. To upgrade diffusers run `pip install --upgrade diffusers[torch]`
|
||||
* 11/7 (v7): Text Encoder supports checkpoint files in different storage formats (it is converted at the time of import, so export will be in normal format). Changed the average value of EPOCH loss to output to the screen. Added a function to save epoch and global step in checkpoint in SD format (add values if there is existing data). The reg_data_dir option is enabled during fine tuning (fine tuning while mixing regularized images). Added dataset_repeats option that is valid for fine tuning (specified when the number of teacher images is small and the epoch is extremely short).
|
||||
@ -1,162 +0,0 @@
|
||||
# Kohya_ss Finetune
|
||||
|
||||
This python utility provide code to run the diffusers fine tuning version found in this note: https://note.com/kohya_ss/n/nbf7ce8d80f29
|
||||
|
||||
## Required Dependencies
|
||||
|
||||
Python 3.10.6 and Git:
|
||||
|
||||
- Python 3.10.6: https://www.python.org/ftp/python/3.10.6/python-3.10.6-amd64.exe
|
||||
- git: https://git-scm.com/download/win
|
||||
|
||||
Give unrestricted script access to powershell so venv can work:
|
||||
|
||||
- Open an administrator powershell window
|
||||
- Type `Set-ExecutionPolicy Unrestricted` and answer A
|
||||
- Close admin powershell window
|
||||
|
||||
## Installation
|
||||
|
||||
Open a regular Powershell terminal and type the following inside:
|
||||
|
||||
```powershell
|
||||
git clone https://github.com/bmaltais/kohya_diffusers_fine_tuning.git
|
||||
cd kohya_diffusers_fine_tuning
|
||||
|
||||
python -m venv --system-site-packages venv
|
||||
.\venv\Scripts\activate
|
||||
|
||||
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
|
||||
pip install --upgrade -r requirements.txt
|
||||
pip install -U -I --no-deps https://github.com/C43H66N12O12S2/stable-diffusion-webui/releases/download/f/xformers-0.0.14.dev0-cp310-cp310-win_amd64.whl
|
||||
|
||||
cp .\bitsandbytes_windows\*.dll .\venv\Lib\site-packages\bitsandbytes\
|
||||
cp .\bitsandbytes_windows\cextension.py .\venv\Lib\site-packages\bitsandbytes\cextension.py
|
||||
cp .\bitsandbytes_windows\main.py .\venv\Lib\site-packages\bitsandbytes\cuda_setup\main.py
|
||||
|
||||
accelerate config
|
||||
|
||||
```
|
||||
|
||||
Answers to accelerate config:
|
||||
|
||||
```txt
|
||||
- 0
|
||||
- 0
|
||||
- NO
|
||||
- NO
|
||||
- All
|
||||
- fp16
|
||||
```
|
||||
|
||||
### Optional: CUDNN 8.6
|
||||
|
||||
This step is optional but can improve the learning speed for NVidia 4090 owners...
|
||||
|
||||
Due to the filesize I can't host the DLLs needed for CUDNN 8.6 on Github, I strongly advise you download them for a speed boost in sample generation (almost 50% on 4090) you can download them from here: https://b1.thefileditch.ch/mwxKTEtelILoIbMbruuM.zip
|
||||
|
||||
To install simply unzip the directory and place the cudnn_windows folder in the root of the kohya_diffusers_fine_tuning repo.
|
||||
|
||||
Run the following command to install:
|
||||
|
||||
```
|
||||
python .\tools\cudann_1.8_install.py
|
||||
```
|
||||
|
||||
## Upgrade
|
||||
|
||||
When a new release comes out you can upgrade your repo with the following command:
|
||||
|
||||
```powershell
|
||||
cd kohya_ss
|
||||
git pull
|
||||
.\venv\Scripts\activate
|
||||
pip install --upgrade -r requirements.txt
|
||||
```
|
||||
|
||||
Once the commands have completed successfully you should be ready to use the new version.
|
||||
|
||||
## Folders configuration
|
||||
|
||||
Simply put all the images you will want to train on in a single directory. It does not matter what size or aspect ratio they have. It is your choice.
|
||||
|
||||
## Captions
|
||||
|
||||
Each file need to be accompanied by a caption file describing what the image is about. For example, if you want to train on cute dog pictures you can put `cute dog` as the caption in every file. You can use the `tools\caption.ps1` sample code to help out with that:
|
||||
|
||||
```powershell
|
||||
$folder = "sample"
|
||||
$file_pattern="*.*"
|
||||
$caption_text="cute dog"
|
||||
|
||||
$files = Get-ChildItem "$folder\$file_pattern" -Include *.png, *.jpg, *.webp -File
|
||||
foreach ($file in $files) {
|
||||
if (-not(Test-Path -Path $folder\"$($file.BaseName).txt" -PathType Leaf)) {
|
||||
New-Item -ItemType file -Path $folder -Name "$($file.BaseName).txt" -Value $caption_text
|
||||
}
|
||||
}
|
||||
|
||||
You can also use the `Captioning` tool found under the `Utilities` tab in the GUI.
|
||||
```
|
||||
|
||||
## GUI
|
||||
|
||||
There is now support for GUI based training using gradio. You can start the complete kohya training GUI interface by running:
|
||||
|
||||
```powershell
|
||||
.\venv\Scripts\activate
|
||||
.\kohya_gui.cmd
|
||||
```
|
||||
|
||||
## CLI
|
||||
|
||||
You can find various examples of how to leverage the `fine_tune.py` in this folder: https://github.com/bmaltais/kohya_ss/tree/master/examples
|
||||
|
||||
## Support
|
||||
|
||||
Drop by the discord server for support: https://discord.com/channels/1041518562487058594/1041518563242020906
|
||||
|
||||
## Change history
|
||||
|
||||
* 12/20 (v9.6) update:
|
||||
- fix issue with config file save and opening
|
||||
* 12/19 (v9.5) update:
|
||||
- Fix file/folder dialog opening behind the browser window
|
||||
- Update GUI layout to be more logical
|
||||
* 12/18 (v9.4) update:
|
||||
- Add WD14 tagging to utilities
|
||||
* 12/18 (v9.3) update:
|
||||
- Add logging option
|
||||
* 12/18 (v9.2) update:
|
||||
- Add BLIP Captioning utility
|
||||
* 12/18 (v9.1) update:
|
||||
- Add Stable Diffusion model conversion utility. Make sure to run `pip upgrade -U -r requirements.txt` after updating to this release as this introduce new pip requirements.
|
||||
* 12/17 (v9) update:
|
||||
- Save model as option added to fine_tune.py
|
||||
- Save model as option added to GUI
|
||||
- Retirement of cli based documentation. Will focus attention to GUI based training
|
||||
* 12/13 (v8):
|
||||
- WD14Tagger now works on its own.
|
||||
- Added support for learning to fp16 up to the gradient. Go to "Building the environment and preparing scripts for Diffusers for more info".
|
||||
* 12/10 (v7):
|
||||
- We have added support for Diffusers 0.10.2.
|
||||
- In addition, we have made other fixes.
|
||||
- For more information, please see the section on "Building the environment and preparing scripts for Diffusers" in our documentation.
|
||||
* 12/6 (v6): We have responded to reports that some models experience an error when saving in SafeTensors format.
|
||||
* 12/5 (v5):
|
||||
- .safetensors format is now supported. Install SafeTensors as "pip install safetensors". When loading, it is automatically determined by extension. Specify use_safetensors options when saving.
|
||||
- Added an option to add any string before the date and time log directory name log_prefix.
|
||||
- Cleaning scripts now work without either captions or tags.
|
||||
* 11/29 (v4):
|
||||
- DiffUsers 0.9.0 is required. Update as "pip install -U diffusers[torch]==0.9.0" in the virtual environment, and update the dependent libraries as "pip install --upgrade -r requirements.txt" if other errors occur.
|
||||
- Compatible with Stable Diffusion v2.0. Add the --v2 option when training (and pre-fetching latents). If you are using 768-v-ema.ckpt or stable-diffusion-2 instead of stable-diffusion-v2-base, add --v_parameterization as well when learning. Learn more about other options.
|
||||
- The minimum resolution and maximum resolution of the bucket can be specified when pre-fetching latents.
|
||||
- Corrected the calculation formula for loss (fixed that it was increasing according to the batch size).
|
||||
- Added options related to the learning rate scheduler.
|
||||
- So that you can download and learn DiffUsers models directly from Hugging Face. In addition, DiffUsers models can be saved during training.
|
||||
- Available even if the clean_captions_and_tags.py is only a caption or a tag.
|
||||
- Other minor fixes such as changing the arguments of the noise scheduler during training.
|
||||
* 11/23 (v3):
|
||||
- Added WD14Tagger tagging script.
|
||||
- A log output function has been added to the fine_tune.py. Also, fixed the double shuffling of data.
|
||||
- Fixed misspelling of options for each script (caption_extention→caption_extension will work for the time being, even if it remains outdated).
|
||||
@ -18,6 +18,8 @@ from library.common_gui import (
|
||||
get_any_file_path,
|
||||
get_saveasfile_path,
|
||||
color_aug_changed,
|
||||
save_inference_file,
|
||||
set_pretrained_model_name_or_path_input,
|
||||
)
|
||||
from library.dreambooth_folder_creation_gui import (
|
||||
gradio_dreambooth_folder_creation_tab,
|
||||
@ -69,7 +71,12 @@ def save_configuration(
|
||||
color_aug,
|
||||
flip_aug,
|
||||
clip_skip,
|
||||
vae,
|
||||
output_name,
|
||||
):
|
||||
# Get list of function parameters and values
|
||||
parameters = list(locals().items())
|
||||
|
||||
original_file_path = file_path
|
||||
|
||||
save_as_bool = True if save_as.get('label') == 'True' else False
|
||||
@ -89,46 +96,18 @@ def save_configuration(
|
||||
|
||||
# Return the values of the variables as a dictionary
|
||||
variables = {
|
||||
'pretrained_model_name_or_path': pretrained_model_name_or_path,
|
||||
'v2': v2,
|
||||
'v_parameterization': v_parameterization,
|
||||
'logging_dir': logging_dir,
|
||||
'train_data_dir': train_data_dir,
|
||||
'reg_data_dir': reg_data_dir,
|
||||
'output_dir': output_dir,
|
||||
'max_resolution': max_resolution,
|
||||
'learning_rate': learning_rate,
|
||||
'lr_scheduler': lr_scheduler,
|
||||
'lr_warmup': lr_warmup,
|
||||
'train_batch_size': train_batch_size,
|
||||
'epoch': epoch,
|
||||
'save_every_n_epochs': save_every_n_epochs,
|
||||
'mixed_precision': mixed_precision,
|
||||
'save_precision': save_precision,
|
||||
'seed': seed,
|
||||
'num_cpu_threads_per_process': num_cpu_threads_per_process,
|
||||
'cache_latent': cache_latent,
|
||||
'caption_extention': caption_extention,
|
||||
'enable_bucket': enable_bucket,
|
||||
'gradient_checkpointing': gradient_checkpointing,
|
||||
'full_fp16': full_fp16,
|
||||
'no_token_padding': no_token_padding,
|
||||
'stop_text_encoder_training': stop_text_encoder_training,
|
||||
'use_8bit_adam': use_8bit_adam,
|
||||
'xformers': xformers,
|
||||
'save_model_as': save_model_as,
|
||||
'shuffle_caption': shuffle_caption,
|
||||
'save_state': save_state,
|
||||
'resume': resume,
|
||||
'prior_loss_weight': prior_loss_weight,
|
||||
'color_aug': color_aug,
|
||||
'flip_aug': flip_aug,
|
||||
'clip_skip': clip_skip,
|
||||
name: value
|
||||
for name, value in parameters # locals().items()
|
||||
if name
|
||||
not in [
|
||||
'file_path',
|
||||
'save_as',
|
||||
]
|
||||
}
|
||||
|
||||
# Save the data to the selected file
|
||||
with open(file_path, 'w') as file:
|
||||
json.dump(variables, file)
|
||||
json.dump(variables, file, indent=2)
|
||||
|
||||
return file_path
|
||||
|
||||
@ -170,65 +149,32 @@ def open_configuration(
|
||||
color_aug,
|
||||
flip_aug,
|
||||
clip_skip,
|
||||
vae,
|
||||
output_name,
|
||||
):
|
||||
# Get list of function parameters and values
|
||||
parameters = list(locals().items())
|
||||
|
||||
original_file_path = file_path
|
||||
file_path = get_file_path(file_path)
|
||||
# print(file_path)
|
||||
|
||||
if not file_path == '' and not file_path == None:
|
||||
# load variables from JSON file
|
||||
with open(file_path, 'r') as f:
|
||||
my_data = json.load(f)
|
||||
my_data_db = json.load(f)
|
||||
print("Loading config...")
|
||||
else:
|
||||
file_path = original_file_path # In case a file_path was provided and the user decide to cancel the open action
|
||||
my_data = {}
|
||||
|
||||
# Return the values of the variables as a dictionary
|
||||
return (
|
||||
file_path,
|
||||
my_data.get(
|
||||
'pretrained_model_name_or_path', pretrained_model_name_or_path
|
||||
),
|
||||
my_data.get('v2', v2),
|
||||
my_data.get('v_parameterization', v_parameterization),
|
||||
my_data.get('logging_dir', logging_dir),
|
||||
my_data.get('train_data_dir', train_data_dir),
|
||||
my_data.get('reg_data_dir', reg_data_dir),
|
||||
my_data.get('output_dir', output_dir),
|
||||
my_data.get('max_resolution', max_resolution),
|
||||
my_data.get('learning_rate', learning_rate),
|
||||
my_data.get('lr_scheduler', lr_scheduler),
|
||||
my_data.get('lr_warmup', lr_warmup),
|
||||
my_data.get('train_batch_size', train_batch_size),
|
||||
my_data.get('epoch', epoch),
|
||||
my_data.get('save_every_n_epochs', save_every_n_epochs),
|
||||
my_data.get('mixed_precision', mixed_precision),
|
||||
my_data.get('save_precision', save_precision),
|
||||
my_data.get('seed', seed),
|
||||
my_data.get(
|
||||
'num_cpu_threads_per_process', num_cpu_threads_per_process
|
||||
),
|
||||
my_data.get('cache_latent', cache_latent),
|
||||
my_data.get('caption_extention', caption_extention),
|
||||
my_data.get('enable_bucket', enable_bucket),
|
||||
my_data.get('gradient_checkpointing', gradient_checkpointing),
|
||||
my_data.get('full_fp16', full_fp16),
|
||||
my_data.get('no_token_padding', no_token_padding),
|
||||
my_data.get('stop_text_encoder_training', stop_text_encoder_training),
|
||||
my_data.get('use_8bit_adam', use_8bit_adam),
|
||||
my_data.get('xformers', xformers),
|
||||
my_data.get('save_model_as', save_model_as),
|
||||
my_data.get('shuffle_caption', shuffle_caption),
|
||||
my_data.get('save_state', save_state),
|
||||
my_data.get('resume', resume),
|
||||
my_data.get('prior_loss_weight', prior_loss_weight),
|
||||
my_data.get('color_aug', color_aug),
|
||||
my_data.get('flip_aug', flip_aug),
|
||||
my_data.get('clip_skip', clip_skip),
|
||||
)
|
||||
my_data_db = {}
|
||||
|
||||
values = [file_path]
|
||||
for key, value in parameters:
|
||||
# Set the value in the dictionary to the corresponding value in `my_data`, or the default value if not found
|
||||
if not key in ['file_path']:
|
||||
values.append(my_data_db.get(key, value))
|
||||
return tuple(values)
|
||||
|
||||
|
||||
def train_model(
|
||||
pretrained_model_name_or_path,
|
||||
v2,
|
||||
@ -265,22 +211,9 @@ def train_model(
|
||||
color_aug,
|
||||
flip_aug,
|
||||
clip_skip,
|
||||
vae,
|
||||
output_name,
|
||||
):
|
||||
def save_inference_file(output_dir, v2, v_parameterization):
|
||||
# Copy inference model for v2 if required
|
||||
if v2 and v_parameterization:
|
||||
print(f'Saving v2-inference-v.yaml as {output_dir}/last.yaml')
|
||||
shutil.copy(
|
||||
f'./v2_inference/v2-inference-v.yaml',
|
||||
f'{output_dir}/last.yaml',
|
||||
)
|
||||
elif v2:
|
||||
print(f'Saving v2-inference.yaml as {output_dir}/last.yaml')
|
||||
shutil.copy(
|
||||
f'./v2_inference/v2-inference.yaml',
|
||||
f'{output_dir}/last.yaml',
|
||||
)
|
||||
|
||||
if pretrained_model_name_or_path == '':
|
||||
msgbox('Source model information is missing')
|
||||
return
|
||||
@ -430,68 +363,21 @@ def train_model(
|
||||
run_cmd += f' --prior_loss_weight={prior_loss_weight}'
|
||||
if int(clip_skip) > 1:
|
||||
run_cmd += f' --clip_skip={str(clip_skip)}'
|
||||
if not vae == '':
|
||||
run_cmd += f' --vae="{vae}"'
|
||||
if not output_name == '':
|
||||
run_cmd += f' --output_name="{output_name}"'
|
||||
|
||||
print(run_cmd)
|
||||
# Run the command
|
||||
subprocess.run(run_cmd)
|
||||
|
||||
# check if output_dir/last is a folder... therefore it is a diffuser model
|
||||
last_dir = pathlib.Path(f'{output_dir}/last')
|
||||
last_dir = pathlib.Path(f'{output_dir}/{output_name}')
|
||||
|
||||
if not last_dir.is_dir():
|
||||
# Copy inference model for v2 if required
|
||||
save_inference_file(output_dir, v2, v_parameterization)
|
||||
|
||||
|
||||
def set_pretrained_model_name_or_path_input(value, v2, v_parameterization):
|
||||
# define a list of substrings to search for
|
||||
substrings_v2 = [
|
||||
'stabilityai/stable-diffusion-2-1-base',
|
||||
'stabilityai/stable-diffusion-2-base',
|
||||
]
|
||||
|
||||
# check if $v2 and $v_parameterization are empty and if $pretrained_model_name_or_path contains any of the substrings in the v2 list
|
||||
if str(value) in substrings_v2:
|
||||
print('SD v2 model detected. Setting --v2 parameter')
|
||||
v2 = True
|
||||
v_parameterization = False
|
||||
|
||||
return value, v2, v_parameterization
|
||||
|
||||
# define a list of substrings to search for v-objective
|
||||
substrings_v_parameterization = [
|
||||
'stabilityai/stable-diffusion-2-1',
|
||||
'stabilityai/stable-diffusion-2',
|
||||
]
|
||||
|
||||
# check if $v2 and $v_parameterization are empty and if $pretrained_model_name_or_path contains any of the substrings in the v_parameterization list
|
||||
if str(value) in substrings_v_parameterization:
|
||||
print(
|
||||
'SD v2 v_parameterization detected. Setting --v2 parameter and --v_parameterization'
|
||||
)
|
||||
v2 = True
|
||||
v_parameterization = True
|
||||
|
||||
return value, v2, v_parameterization
|
||||
|
||||
# define a list of substrings to v1.x
|
||||
substrings_v1_model = [
|
||||
'CompVis/stable-diffusion-v1-4',
|
||||
'runwayml/stable-diffusion-v1-5',
|
||||
]
|
||||
|
||||
if str(value) in substrings_v1_model:
|
||||
v2 = False
|
||||
v_parameterization = False
|
||||
|
||||
return value, v2, v_parameterization
|
||||
|
||||
if value == 'custom':
|
||||
value = ''
|
||||
v2 = False
|
||||
v_parameterization = False
|
||||
|
||||
return value, v2, v_parameterization
|
||||
save_inference_file(output_dir, v2, v_parameterization, output_name)
|
||||
|
||||
|
||||
def UI(username, password):
|
||||
@ -529,10 +415,10 @@ def UI(username, password):
|
||||
|
||||
|
||||
def dreambooth_tab(
|
||||
train_data_dir_input=gr.Textbox(),
|
||||
reg_data_dir_input=gr.Textbox(),
|
||||
output_dir_input=gr.Textbox(),
|
||||
logging_dir_input=gr.Textbox(),
|
||||
train_data_dir=gr.Textbox(),
|
||||
reg_data_dir=gr.Textbox(),
|
||||
output_dir=gr.Textbox(),
|
||||
logging_dir=gr.Textbox(),
|
||||
):
|
||||
dummy_db_true = gr.Label(value=True, visible=False)
|
||||
dummy_db_false = gr.Label(value=False, visible=False)
|
||||
@ -549,32 +435,27 @@ def dreambooth_tab(
|
||||
placeholder="type the configuration file path or use the 'Open' button above to select it...",
|
||||
interactive=True,
|
||||
)
|
||||
# config_file_name.change(
|
||||
# remove_doublequote,
|
||||
# inputs=[config_file_name],
|
||||
# outputs=[config_file_name],
|
||||
# )
|
||||
with gr.Tab('Source model'):
|
||||
# Define the input elements
|
||||
with gr.Row():
|
||||
pretrained_model_name_or_path_input = gr.Textbox(
|
||||
pretrained_model_name_or_path = gr.Textbox(
|
||||
label='Pretrained model name or path',
|
||||
placeholder='enter the path to custom model or name of pretrained model',
|
||||
)
|
||||
pretrained_model_name_or_path_fille = gr.Button(
|
||||
pretrained_model_name_or_path_file = gr.Button(
|
||||
document_symbol, elem_id='open_folder_small'
|
||||
)
|
||||
pretrained_model_name_or_path_fille.click(
|
||||
pretrained_model_name_or_path_file.click(
|
||||
get_any_file_path,
|
||||
inputs=[pretrained_model_name_or_path_input],
|
||||
outputs=pretrained_model_name_or_path_input,
|
||||
inputs=[pretrained_model_name_or_path],
|
||||
outputs=pretrained_model_name_or_path,
|
||||
)
|
||||
pretrained_model_name_or_path_folder = gr.Button(
|
||||
folder_symbol, elem_id='open_folder_small'
|
||||
)
|
||||
pretrained_model_name_or_path_folder.click(
|
||||
get_folder_path,
|
||||
outputs=pretrained_model_name_or_path_input,
|
||||
outputs=pretrained_model_name_or_path,
|
||||
)
|
||||
model_list = gr.Dropdown(
|
||||
label='(Optional) Model Quick Pick',
|
||||
@ -588,7 +469,7 @@ def dreambooth_tab(
|
||||
'CompVis/stable-diffusion-v1-4',
|
||||
],
|
||||
)
|
||||
save_model_as_dropdown = gr.Dropdown(
|
||||
save_model_as = gr.Dropdown(
|
||||
label='Save trained model as',
|
||||
choices=[
|
||||
'same as source model',
|
||||
@ -600,28 +481,28 @@ def dreambooth_tab(
|
||||
value='same as source model',
|
||||
)
|
||||
with gr.Row():
|
||||
v2_input = gr.Checkbox(label='v2', value=True)
|
||||
v_parameterization_input = gr.Checkbox(
|
||||
v2 = gr.Checkbox(label='v2', value=True)
|
||||
v_parameterization = gr.Checkbox(
|
||||
label='v_parameterization', value=False
|
||||
)
|
||||
pretrained_model_name_or_path_input.change(
|
||||
pretrained_model_name_or_path.change(
|
||||
remove_doublequote,
|
||||
inputs=[pretrained_model_name_or_path_input],
|
||||
outputs=[pretrained_model_name_or_path_input],
|
||||
inputs=[pretrained_model_name_or_path],
|
||||
outputs=[pretrained_model_name_or_path],
|
||||
)
|
||||
model_list.change(
|
||||
set_pretrained_model_name_or_path_input,
|
||||
inputs=[model_list, v2_input, v_parameterization_input],
|
||||
inputs=[model_list, v2, v_parameterization],
|
||||
outputs=[
|
||||
pretrained_model_name_or_path_input,
|
||||
v2_input,
|
||||
v_parameterization_input,
|
||||
pretrained_model_name_or_path,
|
||||
v2,
|
||||
v_parameterization,
|
||||
],
|
||||
)
|
||||
|
||||
with gr.Tab('Folders'):
|
||||
with gr.Row():
|
||||
train_data_dir_input = gr.Textbox(
|
||||
train_data_dir = gr.Textbox(
|
||||
label='Image folder',
|
||||
placeholder='Folder where the training folders containing the images are located',
|
||||
)
|
||||
@ -629,9 +510,9 @@ def dreambooth_tab(
|
||||
'📂', elem_id='open_folder_small'
|
||||
)
|
||||
train_data_dir_input_folder.click(
|
||||
get_folder_path, outputs=train_data_dir_input
|
||||
get_folder_path, outputs=train_data_dir
|
||||
)
|
||||
reg_data_dir_input = gr.Textbox(
|
||||
reg_data_dir = gr.Textbox(
|
||||
label='Regularisation folder',
|
||||
placeholder='(Optional) Folder where where the regularization folders containing the images are located',
|
||||
)
|
||||
@ -639,20 +520,18 @@ def dreambooth_tab(
|
||||
'📂', elem_id='open_folder_small'
|
||||
)
|
||||
reg_data_dir_input_folder.click(
|
||||
get_folder_path, outputs=reg_data_dir_input
|
||||
get_folder_path, outputs=reg_data_dir
|
||||
)
|
||||
with gr.Row():
|
||||
output_dir_input = gr.Textbox(
|
||||
label='Output folder',
|
||||
output_dir = gr.Textbox(
|
||||
label='Model output folder',
|
||||
placeholder='Folder to output trained model',
|
||||
)
|
||||
output_dir_input_folder = gr.Button(
|
||||
'📂', elem_id='open_folder_small'
|
||||
)
|
||||
output_dir_input_folder.click(
|
||||
get_folder_path, outputs=output_dir_input
|
||||
)
|
||||
logging_dir_input = gr.Textbox(
|
||||
output_dir_input_folder.click(get_folder_path, outputs=output_dir)
|
||||
logging_dir = gr.Textbox(
|
||||
label='Logging folder',
|
||||
placeholder='Optional: enable logging and output TensorBoard log to this folder',
|
||||
)
|
||||
@ -660,32 +539,39 @@ def dreambooth_tab(
|
||||
'📂', elem_id='open_folder_small'
|
||||
)
|
||||
logging_dir_input_folder.click(
|
||||
get_folder_path, outputs=logging_dir_input
|
||||
get_folder_path, outputs=logging_dir
|
||||
)
|
||||
train_data_dir_input.change(
|
||||
with gr.Row():
|
||||
output_name = gr.Textbox(
|
||||
label='Model output name',
|
||||
placeholder='Name of the model to output',
|
||||
value='last',
|
||||
interactive=True,
|
||||
)
|
||||
train_data_dir.change(
|
||||
remove_doublequote,
|
||||
inputs=[train_data_dir_input],
|
||||
outputs=[train_data_dir_input],
|
||||
inputs=[train_data_dir],
|
||||
outputs=[train_data_dir],
|
||||
)
|
||||
reg_data_dir_input.change(
|
||||
reg_data_dir.change(
|
||||
remove_doublequote,
|
||||
inputs=[reg_data_dir_input],
|
||||
outputs=[reg_data_dir_input],
|
||||
inputs=[reg_data_dir],
|
||||
outputs=[reg_data_dir],
|
||||
)
|
||||
output_dir_input.change(
|
||||
output_dir.change(
|
||||
remove_doublequote,
|
||||
inputs=[output_dir_input],
|
||||
outputs=[output_dir_input],
|
||||
inputs=[output_dir],
|
||||
outputs=[output_dir],
|
||||
)
|
||||
logging_dir_input.change(
|
||||
logging_dir.change(
|
||||
remove_doublequote,
|
||||
inputs=[logging_dir_input],
|
||||
outputs=[logging_dir_input],
|
||||
inputs=[logging_dir],
|
||||
outputs=[logging_dir],
|
||||
)
|
||||
with gr.Tab('Training parameters'):
|
||||
with gr.Row():
|
||||
learning_rate_input = gr.Textbox(label='Learning rate', value=1e-6)
|
||||
lr_scheduler_input = gr.Dropdown(
|
||||
learning_rate = gr.Textbox(label='Learning rate', value=1e-6)
|
||||
lr_scheduler = gr.Dropdown(
|
||||
label='LR Scheduler',
|
||||
choices=[
|
||||
'constant',
|
||||
@ -697,21 +583,21 @@ def dreambooth_tab(
|
||||
],
|
||||
value='constant',
|
||||
)
|
||||
lr_warmup_input = gr.Textbox(label='LR warmup', value=0)
|
||||
lr_warmup = gr.Textbox(label='LR warmup', value=0)
|
||||
with gr.Row():
|
||||
train_batch_size_input = gr.Slider(
|
||||
train_batch_size = gr.Slider(
|
||||
minimum=1,
|
||||
maximum=32,
|
||||
label='Train batch size',
|
||||
value=1,
|
||||
step=1,
|
||||
)
|
||||
epoch_input = gr.Textbox(label='Epoch', value=1)
|
||||
save_every_n_epochs_input = gr.Textbox(
|
||||
epoch = gr.Textbox(label='Epoch', value=1)
|
||||
save_every_n_epochs = gr.Textbox(
|
||||
label='Save every N epochs', value=1
|
||||
)
|
||||
with gr.Row():
|
||||
mixed_precision_input = gr.Dropdown(
|
||||
mixed_precision = gr.Dropdown(
|
||||
label='Mixed precision',
|
||||
choices=[
|
||||
'no',
|
||||
@ -720,7 +606,7 @@ def dreambooth_tab(
|
||||
],
|
||||
value='fp16',
|
||||
)
|
||||
save_precision_input = gr.Dropdown(
|
||||
save_precision = gr.Dropdown(
|
||||
label='Save precision',
|
||||
choices=[
|
||||
'float',
|
||||
@ -729,7 +615,7 @@ def dreambooth_tab(
|
||||
],
|
||||
value='fp16',
|
||||
)
|
||||
num_cpu_threads_per_process_input = gr.Slider(
|
||||
num_cpu_threads_per_process = gr.Slider(
|
||||
minimum=1,
|
||||
maximum=os.cpu_count(),
|
||||
step=1,
|
||||
@ -737,18 +623,18 @@ def dreambooth_tab(
|
||||
value=os.cpu_count(),
|
||||
)
|
||||
with gr.Row():
|
||||
seed_input = gr.Textbox(label='Seed', value=1234)
|
||||
max_resolution_input = gr.Textbox(
|
||||
seed = gr.Textbox(label='Seed', value=1234)
|
||||
max_resolution = gr.Textbox(
|
||||
label='Max resolution',
|
||||
value='512,512',
|
||||
placeholder='512,512',
|
||||
)
|
||||
with gr.Row():
|
||||
caption_extention_input = gr.Textbox(
|
||||
caption_extention = gr.Textbox(
|
||||
label='Caption Extension',
|
||||
placeholder='(Optional) Extension for caption files. default: .caption',
|
||||
)
|
||||
stop_text_encoder_training_input = gr.Slider(
|
||||
stop_text_encoder_training = gr.Slider(
|
||||
minimum=0,
|
||||
maximum=100,
|
||||
value=0,
|
||||
@ -756,24 +642,20 @@ def dreambooth_tab(
|
||||
label='Stop text encoder training',
|
||||
)
|
||||
with gr.Row():
|
||||
enable_bucket_input = gr.Checkbox(
|
||||
label='Enable buckets', value=True
|
||||
)
|
||||
cache_latent_input = gr.Checkbox(label='Cache latent', value=True)
|
||||
use_8bit_adam_input = gr.Checkbox(
|
||||
label='Use 8bit adam', value=True
|
||||
)
|
||||
xformers_input = gr.Checkbox(label='Use xformers', value=True)
|
||||
enable_bucket = gr.Checkbox(label='Enable buckets', value=True)
|
||||
cache_latent = gr.Checkbox(label='Cache latent', value=True)
|
||||
use_8bit_adam = gr.Checkbox(label='Use 8bit adam', value=True)
|
||||
xformers = gr.Checkbox(label='Use xformers', value=True)
|
||||
with gr.Accordion('Advanced Configuration', open=False):
|
||||
with gr.Row():
|
||||
full_fp16_input = gr.Checkbox(
|
||||
full_fp16 = gr.Checkbox(
|
||||
label='Full fp16 training (experimental)', value=False
|
||||
)
|
||||
no_token_padding_input = gr.Checkbox(
|
||||
no_token_padding = gr.Checkbox(
|
||||
label='No token padding', value=False
|
||||
)
|
||||
|
||||
gradient_checkpointing_input = gr.Checkbox(
|
||||
gradient_checkpointing = gr.Checkbox(
|
||||
label='Gradient checkpointing', value=False
|
||||
)
|
||||
|
||||
@ -791,7 +673,7 @@ def dreambooth_tab(
|
||||
color_aug.change(
|
||||
color_aug_changed,
|
||||
inputs=[color_aug],
|
||||
outputs=[cache_latent_input],
|
||||
outputs=[cache_latent],
|
||||
)
|
||||
clip_skip = gr.Slider(
|
||||
label='Clip skip', value='1', minimum=1, maximum=12, step=1
|
||||
@ -806,48 +688,54 @@ def dreambooth_tab(
|
||||
prior_loss_weight = gr.Number(
|
||||
label='Prior loss weight', value=1.0
|
||||
)
|
||||
vae = gr.Textbox(
|
||||
label='VAE',
|
||||
placeholder='(Optiona) path to checkpoint of vae to replace for training',
|
||||
)
|
||||
vae_button = gr.Button('📂', elem_id='open_folder_small')
|
||||
vae_button.click(get_any_file_path, outputs=vae)
|
||||
with gr.Tab('Tools'):
|
||||
gr.Markdown(
|
||||
'This section provide Dreambooth tools to help setup your dataset...'
|
||||
)
|
||||
gradio_dreambooth_folder_creation_tab(
|
||||
train_data_dir_input=train_data_dir_input,
|
||||
reg_data_dir_input=reg_data_dir_input,
|
||||
output_dir_input=output_dir_input,
|
||||
logging_dir_input=logging_dir_input,
|
||||
train_data_dir_input=train_data_dir,
|
||||
reg_data_dir_input=reg_data_dir,
|
||||
output_dir_input=output_dir,
|
||||
logging_dir_input=logging_dir,
|
||||
)
|
||||
|
||||
button_run = gr.Button('Train model')
|
||||
|
||||
|
||||
settings_list = [
|
||||
pretrained_model_name_or_path_input,
|
||||
v2_input,
|
||||
v_parameterization_input,
|
||||
logging_dir_input,
|
||||
train_data_dir_input,
|
||||
reg_data_dir_input,
|
||||
output_dir_input,
|
||||
max_resolution_input,
|
||||
learning_rate_input,
|
||||
lr_scheduler_input,
|
||||
lr_warmup_input,
|
||||
train_batch_size_input,
|
||||
epoch_input,
|
||||
save_every_n_epochs_input,
|
||||
mixed_precision_input,
|
||||
save_precision_input,
|
||||
seed_input,
|
||||
num_cpu_threads_per_process_input,
|
||||
cache_latent_input,
|
||||
caption_extention_input,
|
||||
enable_bucket_input,
|
||||
gradient_checkpointing_input,
|
||||
full_fp16_input,
|
||||
no_token_padding_input,
|
||||
stop_text_encoder_training_input,
|
||||
use_8bit_adam_input,
|
||||
xformers_input,
|
||||
save_model_as_dropdown,
|
||||
pretrained_model_name_or_path,
|
||||
v2,
|
||||
v_parameterization,
|
||||
logging_dir,
|
||||
train_data_dir,
|
||||
reg_data_dir,
|
||||
output_dir,
|
||||
max_resolution,
|
||||
learning_rate,
|
||||
lr_scheduler,
|
||||
lr_warmup,
|
||||
train_batch_size,
|
||||
epoch,
|
||||
save_every_n_epochs,
|
||||
mixed_precision,
|
||||
save_precision,
|
||||
seed,
|
||||
num_cpu_threads_per_process,
|
||||
cache_latent,
|
||||
caption_extention,
|
||||
enable_bucket,
|
||||
gradient_checkpointing,
|
||||
full_fp16,
|
||||
no_token_padding,
|
||||
stop_text_encoder_training,
|
||||
use_8bit_adam,
|
||||
xformers,
|
||||
save_model_as,
|
||||
shuffle_caption,
|
||||
save_state,
|
||||
resume,
|
||||
@ -855,6 +743,8 @@ def dreambooth_tab(
|
||||
color_aug,
|
||||
flip_aug,
|
||||
clip_skip,
|
||||
vae,
|
||||
output_name,
|
||||
]
|
||||
|
||||
button_open_config.click(
|
||||
@ -881,10 +771,10 @@ def dreambooth_tab(
|
||||
)
|
||||
|
||||
return (
|
||||
train_data_dir_input,
|
||||
reg_data_dir_input,
|
||||
output_dir_input,
|
||||
logging_dir_input,
|
||||
train_data_dir,
|
||||
reg_data_dir,
|
||||
output_dir,
|
||||
logging_dir,
|
||||
)
|
||||
|
||||
|
||||
|
||||
1356
fine_tune.py
1356
fine_tune.py
File diff suppressed because it is too large
Load Diff
465
fine_tune_README.md
Normal file
465
fine_tune_README.md
Normal file
@ -0,0 +1,465 @@
|
||||
It is a fine tuning that corresponds to NovelAI's proposed learning method, automatic captioning, tagging, Windows + VRAM 12GB (for v1.4/1.5) environment, etc.
|
||||
|
||||
## overview
|
||||
Fine tuning of U-Net of Stable Diffusion using Diffusers. It corresponds to the following improvements in NovelAI's article (For Aspect Ratio Bucketing, I referred to NovelAI's code, but the final code is all original).
|
||||
|
||||
* Use the output of the penultimate layer instead of the last layer of CLIP (Text Encoder).
|
||||
* Learning at non-square resolutions (Aspect Ratio Bucketing).
|
||||
* Extend token length from 75 to 225.
|
||||
* Captioning with BLIP (automatic creation of captions), automatic tagging with DeepDanbooru or WD14Tagger.
|
||||
* Also supports Hypernetwork learning.
|
||||
* Supports Stable Diffusion v2.0 (base and 768/v).
|
||||
* By acquiring the output of VAE in advance and saving it to disk, we aim to save memory and speed up learning.
|
||||
|
||||
Text Encoder is not trained by default. For fine tuning of the whole model, it seems common to learn only U-Net (NovelAI seems to be the same). Text Encoder can also be learned as an option.
|
||||
|
||||
## Additional features
|
||||
### Change CLIP output
|
||||
CLIP (Text Encoder) converts the text into features in order to reflect the prompt in the image. Stable diffusion uses the output of the last layer of CLIP, but you can change it to use the output of the penultimate layer. According to NovelAI, this will reflect prompts more accurately.
|
||||
It is also possible to use the output of the last layer as is.
|
||||
*Stable Diffusion 2.0 uses the penultimate layer by default. Do not specify the clip_skip option.
|
||||
|
||||
### Training in non-square resolutions
|
||||
Stable Diffusion is trained at 512\*512, but also at resolutions such as 256\*1024 and 384\*640. It is expected that this will reduce the cropped portion and learn the relationship between prompts and images more correctly.
|
||||
The learning resolution is adjusted vertically and horizontally in units of 64 pixels within a range that does not exceed the resolution area (= memory usage) given as a parameter.
|
||||
|
||||
In machine learning, it is common to unify all input sizes, but there are no particular restrictions, and in fact it is okay as long as they are unified within the same batch. NovelAI's bucketing seems to refer to classifying training data in advance for each learning resolution according to the aspect ratio. And by creating a batch with the images in each bucket, the image size of the batch is unified.
|
||||
|
||||
### Extending token length from 75 to 225
|
||||
Stable diffusion has a maximum of 75 tokens (77 tokens including the start and end), but we will extend it to 225 tokens.
|
||||
However, the maximum length that CLIP accepts is 75 tokens, so in the case of 225 tokens, we simply divide it into thirds, call CLIP, and then concatenate the results.
|
||||
|
||||
*I'm not sure if this is the preferred implementation. It seems to be working for now. Especially in 2.0, there is no implementation that can be used as a reference, so I have implemented it independently.
|
||||
|
||||
*Automatic1111's Web UI seems to divide the text with commas in mind, but in my case, it's a simple division.
|
||||
|
||||
## Environmental arrangement
|
||||
|
||||
See the [README](./README-en.md) in this repository.
|
||||
|
||||
## Preparing teacher data
|
||||
|
||||
Prepare the image data you want to learn and put it in any folder. No prior preparation such as resizing is required.
|
||||
However, for images that are smaller than the training resolution, it is recommended to enlarge them while maintaining the quality using super-resolution.
|
||||
|
||||
It also supports multiple teacher data folders. Preprocessing will be executed for each folder.
|
||||
|
||||
For example, store an image like this:
|
||||
|
||||
|
||||
|
||||
## Automatic captioning
|
||||
Skip if you just want to learn tags without captions.
|
||||
|
||||
Also, when preparing captions manually, prepare them in the same directory as the teacher data image, with the same file name, extension .caption, etc. Each file should be a text file with only one line.
|
||||
|
||||
### Captioning with BLIP
|
||||
|
||||
The latest version no longer requires BLIP downloads, weight downloads, and additional virtual environments. Works as-is.
|
||||
|
||||
Run make_captions.py in the finetune folder.
|
||||
|
||||
```
|
||||
python finetune\make_captions.py --batch_size <batch size> <teacher data folder>
|
||||
```
|
||||
|
||||
If the batch size is 8 and the training data is placed in the parent folder train_data, it will be as follows.
|
||||
|
||||
```
|
||||
python finetune\make_captions.py --batch_size 8 ..\train_data
|
||||
```
|
||||
|
||||
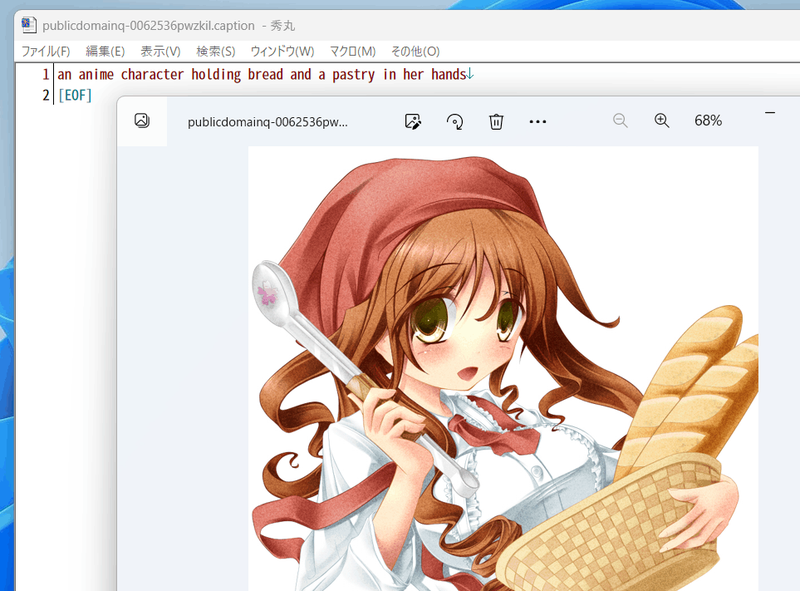
A caption file is created in the same directory as the teacher data image with the same file name and extension .caption.
|
||||
|
||||
Increase or decrease batch_size according to the VRAM capacity of the GPU. Bigger is faster (I think 12GB of VRAM can be a little more).
|
||||
You can specify the maximum length of the caption with the max_length option. Default is 75. It may be longer if the model is trained with a token length of 225.
|
||||
You can change the caption extension with the caption_extension option. Default is .caption (.txt conflicts with DeepDanbooru described later).
|
||||
|
||||
If there are multiple teacher data folders, execute for each folder.
|
||||
|
||||
Note that the inference is random, so the results will change each time you run it. If you want to fix it, specify a random number seed like "--seed 42" with the --seed option.
|
||||
|
||||
For other options, please refer to the help with --help (there seems to be no documentation for the meaning of the parameters, so you have to look at the source).
|
||||
|
||||
A caption file is generated with the extension .caption by default.
|
||||
|
||||
|
||||
|
||||
For example, with captions like:
|
||||
|
||||
|
||||
|
||||
## Tagged by DeepDanbooru
|
||||
If you do not want to tag the danbooru tag itself, please proceed to "Preprocessing of caption and tag information".
|
||||
|
||||
Tagging is done with DeepDanbooru or WD14Tagger. WD14Tagger seems to be more accurate. If you want to tag with WD14Tagger, skip to the next chapter.
|
||||
|
||||
### Environmental arrangement
|
||||
Clone DeepDanbooru https://github.com/KichangKim/DeepDanbooru into your working folder, or download the zip and extract it. I unzipped it.
|
||||
Also, download deepdanbooru-v3-20211112-sgd-e28.zip from Assets of "DeepDanbooru Pretrained Model v3-20211112-sgd-e28" on the DeepDanbooru Releases page https://github.com/KichangKim/DeepDanbooru/releases and extract it to the DeepDanbooru folder.
|
||||
|
||||
Download from below. Click to open Assets and download from there.
|
||||
|
||||
|
||||
|
||||
Make a directory structure like this
|
||||
|
||||
|
||||
|
||||
Install the necessary libraries for the Diffusers environment. Go to the DeepDanbooru folder and install it (I think it's actually just adding tensorflow-io).
|
||||
|
||||
```
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
Next, install DeepDanbooru itself.
|
||||
|
||||
```
|
||||
pip install .
|
||||
```
|
||||
|
||||
This completes the preparation of the environment for tagging.
|
||||
|
||||
### Implementing tagging
|
||||
Go to DeepDanbooru's folder and run deepdanbooru to tag.
|
||||
|
||||
```
|
||||
deepdanbooru evaluate <teacher data folder> --project-path deepdanbooru-v3-20211112-sgd-e28 --allow-folder --save-txt
|
||||
```
|
||||
|
||||
If you put the training data in the parent folder train_data, it will be as follows.
|
||||
|
||||
```
|
||||
deepdanbooru evaluate ../train_data --project-path deepdanbooru-v3-20211112-sgd-e28 --allow-folder --save-txt
|
||||
```
|
||||
|
||||
A tag file is created in the same directory as the teacher data image with the same file name and extension .txt. It is slow because it is processed one by one.
|
||||
|
||||
If there are multiple teacher data folders, execute for each folder.
|
||||
|
||||
It is generated as follows.
|
||||
|
||||
|
||||
|
||||
A tag is attached like this (great amount of information...).
|
||||
|
||||
|
||||
|
||||
## Tagging with WD14Tagger
|
||||
This procedure uses WD14Tagger instead of DeepDanbooru.
|
||||
|
||||
Use the tagger used in Mr. Automatic1111's WebUI. I referred to the information on this github page (https://github.com/toriato/stable-diffusion-webui-wd14-tagger#mrsmilingwolfs-model-aka-waifu-diffusion-14-tagger).
|
||||
|
||||
The modules required for the initial environment maintenance have already been installed. Weights are automatically downloaded from Hugging Face.
|
||||
|
||||
### Implementing tagging
|
||||
Run the script to do the tagging.
|
||||
```
|
||||
python tag_images_by_wd14_tagger.py --batch_size <batch size> <teacher data folder>
|
||||
```
|
||||
|
||||
If you put the training data in the parent folder train_data, it will be as follows.
|
||||
```
|
||||
python tag_images_by_wd14_tagger.py --batch_size 4 ..\train_data
|
||||
```
|
||||
|
||||
The model file will be automatically downloaded to the wd14_tagger_model folder on first launch (folder can be changed in options). It will be as follows.
|
||||
|
||||
|
||||
|
||||
A tag file is created in the same directory as the teacher data image with the same file name and extension .txt.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
With the thresh option, you can specify the number of confidences of the determined tag to attach the tag. The default is 0.35, same as the WD14Tagger sample. Lower values give more tags, but less accuracy.
|
||||
Increase or decrease batch_size according to the VRAM capacity of the GPU. Bigger is faster (I think 12GB of VRAM can be a little more). You can change the tag file extension with the caption_extension option. Default is .txt.
|
||||
You can specify the folder where the model is saved with the model_dir option.
|
||||
Also, if you specify the force_download option, the model will be re-downloaded even if there is a save destination folder.
|
||||
|
||||
If there are multiple teacher data folders, execute for each folder.
|
||||
|
||||
## Preprocessing caption and tag information
|
||||
|
||||
Combine captions and tags into a single file as metadata for easy processing from scripts.
|
||||
|
||||
### Caption preprocessing
|
||||
|
||||
To put captions into the metadata, run the following in your working folder (if you don't use captions for learning, you don't need to run this) (it's actually a single line, and so on).
|
||||
|
||||
```
|
||||
python merge_captions_to_metadata.py <teacher data folder>
|
||||
--in_json <metadata file name to read>
|
||||
<metadata file name>
|
||||
```
|
||||
|
||||
The metadata file name is an arbitrary name.
|
||||
If the training data is train_data, there is no metadata file to read, and the metadata file is meta_cap.json, it will be as follows.
|
||||
|
||||
```
|
||||
python merge_captions_to_metadata.py train_data meta_cap.json
|
||||
```
|
||||
|
||||
You can specify the caption extension with the caption_extension option.
|
||||
|
||||
If there are multiple teacher data folders, please specify the full_path argument (metadata will have full path information). Then run it for each folder.
|
||||
|
||||
```
|
||||
python merge_captions_to_metadata.py --full_path
|
||||
train_data1 meta_cap1.json
|
||||
python merge_captions_to_metadata.py --full_path --in_json meta_cap1.json
|
||||
train_data2 meta_cap2.json
|
||||
```
|
||||
|
||||
If in_json is omitted, if there is a write destination metadata file, it will be read from there and overwritten there.
|
||||
|
||||
__*It is safe to rewrite the in_json option and the write destination each time and write to a separate metadata file. __
|
||||
|
||||
### Tag preprocessing
|
||||
|
||||
Similarly, tags are also collected in metadata (no need to do this if tags are not used for learning).
|
||||
```
|
||||
python merge_dd_tags_to_metadata.py <teacher data folder>
|
||||
--in_json <metadata file name to load>
|
||||
<metadata file name to write>
|
||||
```
|
||||
|
||||
With the same directory structure as above, when reading meta_cap.json and writing to meta_cap_dd.json, it will be as follows.
|
||||
```
|
||||
python merge_dd_tags_to_metadata.py train_data --in_json meta_cap.json meta_cap_dd.json
|
||||
```
|
||||
|
||||
If you have multiple teacher data folders, please specify the full_path argument. Then run it for each folder.
|
||||
|
||||
```
|
||||
python merge_dd_tags_to_metadata.py --full_path --in_json meta_cap2.json
|
||||
train_data1 meta_cap_dd1.json
|
||||
python merge_dd_tags_to_metadata.py --full_path --in_json meta_cap_dd1.json
|
||||
train_data2 meta_cap_dd2.json
|
||||
```
|
||||
|
||||
If in_json is omitted, if there is a write destination metadata file, it will be read from there and overwritten there.
|
||||
|
||||
__*It is safe to rewrite the in_json option and the write destination each time and write to a separate metadata file. __
|
||||
|
||||
### Cleaning captions and tags
|
||||
Up to this point, captions and DeepDanbooru tags have been put together in the metadata file. However, captions with automatic captioning are subtle due to spelling variations (*), and tags include underscores and ratings (in the case of DeepDanbooru), so the editor's replacement function etc. You should use it to clean your captions and tags.
|
||||
|
||||
*For example, when learning a girl in an anime picture, there are variations in captions such as girl/girls/woman/women. Also, it may be more appropriate to simply use "girl" for things like "anime girl".
|
||||
|
||||
A script for cleaning is provided, so please edit the contents of the script according to the situation and use it.
|
||||
|
||||
(It is no longer necessary to specify the teacher data folder. All data in the metadata will be cleaned.)
|
||||
|
||||
```
|
||||
python clean_captions_and_tags.py <metadata file name to read> <metadata file name to write>
|
||||
```
|
||||
|
||||
Please note that --in_json is not included. For example:
|
||||
|
||||
```
|
||||
python clean_captions_and_tags.py meta_cap_dd.json meta_clean.json
|
||||
```
|
||||
|
||||
Preprocessing of captions and tags is now complete.
|
||||
|
||||
## Get latents in advance
|
||||
|
||||
In order to speed up the learning, we acquire the latent representation of the image in advance and save it to disk. At the same time, bucketing (classifying the training data according to the aspect ratio) is performed.
|
||||
|
||||
In your working folder, type:
|
||||
```
|
||||
python prepare_buckets_latents.py <teacher data folder>
|
||||
<metadata file name to read> <metadata file name to write>
|
||||
<model name or checkpoint for fine tuning>
|
||||
--batch_size <batch size>
|
||||
--max_resolution <resolution width, height>
|
||||
--mixed_precision <precision>
|
||||
```
|
||||
|
||||
If the model is model.ckpt, batch size 4, training resolution is 512\*512, precision is no (float32), read metadata from meta_clean.json and write to meta_lat.json:
|
||||
|
||||
```
|
||||
python prepare_buckets_latents.py
|
||||
train_data meta_clean.json meta_lat.json model.ckpt
|
||||
--batch_size 4 --max_resolution 512,512 --mixed_precision no
|
||||
```
|
||||
|
||||
Latents are saved in numpy npz format in the teacher data folder.
|
||||
|
||||
Specify the --v2 option when loading a Stable Diffusion 2.0 model (--v_parameterization is not required).
|
||||
|
||||
You can specify the minimum resolution size with the --min_bucket_reso option and the maximum size with the --max_bucket_reso option. The defaults are 256 and 1024 respectively. For example, specifying a minimum size of 384 will not use resolutions such as 256\*1024 or 320\*768.
|
||||
If you increase the resolution to something like 768\*768, you should specify something like 1280 for the maximum size.
|
||||
|
||||
If you specify the --flip_aug option, it will perform horizontal flip augmentation (data augmentation). You can artificially double the amount of data, but if you specify it when the data is not left-right symmetrical (for example, character appearance, hairstyle, etc.), learning will not go well.
|
||||
(This is a simple implementation that acquires the latents for the flipped image and saves the \*\_flip.npz file. No options are required for fline_tune.py. If there is a file with \_flip, Randomly load a file without
|
||||
|
||||
The batch size may be increased a little more even with 12GB of VRAM.
|
||||
The resolution is a number divisible by 64, and is specified by "width, height". The resolution is directly linked to the memory size during fine tuning. 512,512 seems to be the limit with VRAM 12GB (*). 16GB may be raised to 512,704 or 512,768. Even with 256, 256, etc., it seems to be difficult with 8GB of VRAM (because parameters and optimizers require a certain amount of memory regardless of resolution).
|
||||
|
||||
*There was also a report that learning batch size 1 worked with 12GB VRAM and 640,640.
|
||||
|
||||
The result of bucketing is displayed as follows.
|
||||
|
||||
|
||||
|
||||
If you have multiple teacher data folders, please specify the full_path argument. Then run it for each folder.
|
||||
```
|
||||
python prepare_buckets_latents.py --full_path
|
||||
train_data1 meta_clean.json meta_lat1.json model.ckpt
|
||||
--batch_size 4 --max_resolution 512,512 --mixed_precision no
|
||||
|
||||
python prepare_buckets_latents.py --full_path
|
||||
train_data2 meta_lat1.json meta_lat2.json model.ckpt
|
||||
--batch_size 4 --max_resolution 512,512 --mixed_precision no
|
||||
|
||||
```
|
||||
It is possible to make the read source and write destination the same, but separate is safer.
|
||||
|
||||
__*It is safe to rewrite the argument each time and write it to a separate metadata file. __
|
||||
|
||||
|
||||
## Run training
|
||||
For example: Below are the settings for saving memory.
|
||||
```
|
||||
accelerate launch --num_cpu_threads_per_process 8 fine_tune.py
|
||||
--pretrained_model_name_or_path=model.ckpt
|
||||
--in_json meta_lat.json
|
||||
--train_data_dir=train_data
|
||||
--output_dir=fine_tuned
|
||||
--shuffle_caption
|
||||
--train_batch_size=1 --learning_rate=5e-6 --max_train_steps=10000
|
||||
--use_8bit_adam --xformers --gradient_checkpointing
|
||||
--mixed_precision=bf16
|
||||
--save_every_n_epochs=4
|
||||
```
|
||||
|
||||
It seems to be good to specify the number of CPU cores for num_cpu_threads_per_process of accelerate.
|
||||
|
||||
Specify the model to be trained in pretrained_model_name_or_path (Stable Diffusion checkpoint or Diffusers model). Stable Diffusion checkpoint supports .ckpt and .safetensors (automatically determined by extension).
|
||||
|
||||
Specifies the metadata file when caching latent to in_json.
|
||||
|
||||
Specify the training data folder for train_data_dir and the output destination folder for the trained model for output_dir.
|
||||
|
||||
If shuffle_caption is specified, captions and tags are shuffled and learned in units separated by commas (this is the method used in Waifu Diffusion v1.3).
|
||||
(You can keep some of the leading tokens fixed without shuffling. See keep_tokens for other options.)
|
||||
|
||||
Specify the batch size in train_batch_size. Specify 1 or 2 for VRAM 12GB. The number that can be specified also changes depending on the resolution.
|
||||
The actual amount of data used for training is "batch size x number of steps". When increasing the batch size, the number of steps can be decreased accordingly.
|
||||
|
||||
Specify the learning rate in learning_rate. For example Waifu Diffusion v1.3 seems to be 5e-6.
|
||||
Specify the number of steps in max_train_steps.
|
||||
|
||||
Specify use_8bit_adam to use the 8-bit Adam Optimizer. It saves memory and speeds up, but accuracy may decrease.
|
||||
|
||||
Specifying xformers replaces CrossAttention to save memory and speed up.
|
||||
* As of 11/9, xformers will cause an error in float32 learning, so please use bf16/fp16 or use memory-saving CrossAttention with mem_eff_attn instead (speed is inferior to xformers).
|
||||
|
||||
Enable intermediate saving of gradients in gradient_checkpointing. It's slower, but uses less memory.
|
||||
|
||||
Specifies whether to use mixed precision with mixed_precision. Specifying "fp16" or "bf16" saves memory, but accuracy is inferior.
|
||||
"fp16" and "bf16" use almost the same amount of memory, and it is said that bf16 has better learning results (I didn't feel much difference in the range I tried).
|
||||
If "no" is specified, it will not be used (it will be float32).
|
||||
|
||||
* It seems that an error will occur when reading checkpoints learned with bf16 with Mr. AUTOMATIC1111's Web UI. This seems to be because the data type bfloat16 causes an error in the Web UI model safety checker. Save in fp16 or float32 format with the save_precision option. Or it seems to be good to store it in safetytensors format.
|
||||
|
||||
Specifying save_every_n_epochs will save the model being trained every time that many epochs have passed.
|
||||
|
||||
### Supports Stable Diffusion 2.0
|
||||
Specify the --v2 option when using Hugging Face's stable-diffusion-2-base, and specify both --v2 and --v_parameterization options when using stable-diffusion-2 or 768-v-ema.ckpt please.
|
||||
|
||||
### Increase accuracy and speed when memory is available
|
||||
First, removing gradient_checkpointing will speed it up. However, the batch size that can be set is reduced, so please set while looking at the balance between accuracy and speed.
|
||||
|
||||
Increasing the batch size increases speed and accuracy. Increase the speed while checking the speed per data within the range where the memory is sufficient (the speed may actually decrease when the memory is at the limit).
|
||||
|
||||
### Change CLIP output used
|
||||
Specifying 2 for the clip_skip option uses the output of the next-to-last layer. If 1 or option is omitted, the last layer is used.
|
||||
The learned model should be able to be inferred by Automatic1111's web UI.
|
||||
|
||||
*SD2.0 uses the second layer from the back by default, so please do not specify it when learning SD2.0.
|
||||
|
||||
If the model being trained was originally trained to use the second layer, 2 is a good value.
|
||||
|
||||
If you were using the last layer instead, the entire model would have been trained on that assumption. Therefore, if you train again using the second layer, you may need a certain number of teacher data and longer learning to obtain the desired learning result.
|
||||
|
||||
### Extending Token Length
|
||||
You can learn by extending the token length by specifying 150 or 225 for max_token_length.
|
||||
The learned model should be able to be inferred by Automatic1111's web UI.
|
||||
|
||||
As with clip_skip, learning with a length different from the learning state of the model may require a certain amount of teacher data and a longer learning time.
|
||||
|
||||
### Save learning log
|
||||
Specify the log save destination folder in the logging_dir option. Logs in TensorBoard format are saved.
|
||||
|
||||
For example, if you specify --logging_dir=logs, a logs folder will be created in your working folder, and logs will be saved in the date/time folder.
|
||||
Also, if you specify the --log_prefix option, the specified string will be added before the date and time. Use "--logging_dir=logs --log_prefix=fine_tune_style1" for identification.
|
||||
|
||||
To check the log with TensorBoard, open another command prompt and enter the following in the working folder (I think tensorboard is installed when Diffusers is installed, but if it is not installed, pip install Please put it in tensorboard).
|
||||
```
|
||||
tensorboard --logdir=logs
|
||||
```
|
||||
|
||||
### Learning Hypernetworks
|
||||
It will be explained in another article.
|
||||
|
||||
### Learning with fp16 gradient (experimental feature)
|
||||
The full_fp16 option will change the gradient from normal float32 to float16 (fp16) and learn (it seems to be full fp16 learning instead of mixed precision). As a result, it seems that the SD1.x 512*512 size can be learned with a VRAM usage of less than 8GB, and the SD2.x 512*512 size can be learned with a VRAM usage of less than 12GB.
|
||||
|
||||
Specify fp16 in advance in accelerate config and optionally set mixed_precision="fp16" (does not work with bf16).
|
||||
|
||||
To minimize memory usage, use the xformers, use_8bit_adam, gradient_checkpointing options and set train_batch_size to 1.
|
||||
(If you can afford it, increasing the train_batch_size step by step should improve the accuracy a little.)
|
||||
|
||||
It is realized by patching the PyTorch source (confirmed with PyTorch 1.12.1 and 1.13.0). The accuracy will drop considerably, and the probability of learning failure on the way will also increase. The setting of the learning rate and the number of steps seems to be severe. Please be aware of them and use them at your own risk.
|
||||
|
||||
### Other Options
|
||||
|
||||
#### keep_tokens
|
||||
If a number is specified, the specified number of tokens (comma-separated strings) from the beginning of the caption are fixed without being shuffled.
|
||||
|
||||
If there are both captions and tags, the prompts during learning will be concatenated like "caption, tag 1, tag 2...", so if you set "--keep_tokens=1", the caption will always be at the beginning during learning. will come.
|
||||
|
||||
#### dataset_repeats
|
||||
If the number of data sets is extremely small, the epoch will end soon (it will take some time at the epoch break), so please specify a numerical value and multiply the data by some to make the epoch longer.
|
||||
|
||||
#### train_text_encoder
|
||||
Text Encoder is also a learning target. Slightly increased memory usage.
|
||||
|
||||
In normal fine tuning, the Text Encoder is not targeted for training (probably because U-Net is trained to follow the output of the Text Encoder), but if the number of training data is small, the Text Encoder is trained like DreamBooth. also seems to be valid.
|
||||
|
||||
#### save_precision
|
||||
The data format when saving checkpoints can be specified from float, fp16, and bf16 (if not specified, it is the same as the data format during learning). It saves disk space, but the model produces different results. Also, if you specify float or fp16, you should be able to read it on Mr. 1111's Web UI.
|
||||
|
||||
*For VAE, the data format of the original checkpoint will remain, so the model size may not be reduced to a little over 2GB even with fp16.
|
||||
|
||||
#### save_model_as
|
||||
Specify the save format of the model. Specify one of ckpt, safetensors, diffusers, diffusers_safetensors.
|
||||
|
||||
When reading Stable Diffusion format (ckpt or safetensors) and saving in Diffusers format, missing information is supplemented by dropping v1.5 or v2.1 information from Hugging Face.
|
||||
|
||||
#### use_safetensors
|
||||
This option saves checkpoints in safetyensors format. The save format will be the default (same format as loaded).
|
||||
|
||||
#### save_state and resume
|
||||
The save_state option saves the learning state of the optimizer, etc. in addition to the checkpoint in the folder when saving midway and at the final save. This avoids a decrease in accuracy when learning is resumed after being interrupted (since the optimizer optimizes while having a state, if the state is reset, the optimization must be performed again from the initial state. not). Note that the number of steps is not saved due to Accelerate specifications.
|
||||
|
||||
When starting the script, you can resume by specifying the folder where the state is saved with the resume option.
|
||||
|
||||
Please note that the learning state will be about 5 GB per save, so please be careful of the disk capacity.
|
||||
|
||||
#### gradient_accumulation_steps
|
||||
Updates the gradient in batches for the specified number of steps. Has a similar effect to increasing the batch size, but consumes slightly more memory.
|
||||
|
||||
*The Accelerate specification does not support multiple learning models, so if you set Text Encoder as the learning target and specify a value of 2 or more for this option, an error may occur.
|
||||
|
||||
#### lr_scheduler / lr_warmup_steps
|
||||
You can choose the learning rate scheduler from linear, cosine, cosine_with_restarts, polynomial, constant, constant_with_warmup with the lr_scheduler option. Default is constant.
|
||||
|
||||
With lr_warmup_steps, you can specify the number of steps to warm up the scheduler (gradually changing the learning rate). Please do your own research for details.
|
||||
|
||||
#### diffusers_xformers
|
||||
Uses Diffusers' xformers feature rather than the script's own xformers replacement feature. Hypernetwork learning is no longer possible.
|
||||
465
fine_tune_README_ja.md
Normal file
465
fine_tune_README_ja.md
Normal file
@ -0,0 +1,465 @@
|
||||
NovelAIの提案した学習手法、自動キャプションニング、タグ付け、Windows+VRAM 12GB(v1.4/1.5の場合)環境等に対応したfine tuningです。
|
||||
|
||||
## 概要
|
||||
Diffusersを用いてStable DiffusionのU-Netのfine tuningを行います。NovelAIの記事にある以下の改善に対応しています(Aspect Ratio BucketingについてはNovelAIのコードを参考にしましたが、最終的なコードはすべてオリジナルです)。
|
||||
|
||||
* CLIP(Text Encoder)の最後の層ではなく最後から二番目の層の出力を用いる。
|
||||
* 正方形以外の解像度での学習(Aspect Ratio Bucketing) 。
|
||||
* トークン長を75から225に拡張する。
|
||||
* BLIPによるキャプショニング(キャプションの自動作成)、DeepDanbooruまたはWD14Taggerによる自動タグ付けを行う。
|
||||
* Hypernetworkの学習にも対応する。
|
||||
* Stable Diffusion v2.0(baseおよび768/v)に対応。
|
||||
* VAEの出力をあらかじめ取得しディスクに保存しておくことで、学習の省メモリ化、高速化を図る。
|
||||
|
||||
デフォルトではText Encoderの学習は行いません。モデル全体のfine tuningではU-Netだけを学習するのが一般的なようです(NovelAIもそのようです)。オプション指定でText Encoderも学習対象とできます。
|
||||
|
||||
## 追加機能について
|
||||
### CLIPの出力の変更
|
||||
プロンプトを画像に反映するため、テキストの特徴量への変換を行うのがCLIP(Text Encoder)です。Stable DiffusionではCLIPの最後の層の出力を用いていますが、それを最後から二番目の層の出力を用いるよう変更できます。NovelAIによると、これによりより正確にプロンプトが反映されるようになるとのことです。
|
||||
元のまま、最後の層の出力を用いることも可能です。
|
||||
※Stable Diffusion 2.0では最後から二番目の層をデフォルトで使います。clip_skipオプションを指定しないでください。
|
||||
|
||||
### 正方形以外の解像度での学習
|
||||
Stable Diffusionは512\*512で学習されていますが、それに加えて256\*1024や384\*640といった解像度でも学習します。これによりトリミングされる部分が減り、より正しくプロンプトと画像の関係が学習されることが期待されます。
|
||||
学習解像度はパラメータとして与えられた解像度の面積(=メモリ使用量)を超えない範囲で、64ピクセル単位で縦横に調整、作成されます。
|
||||
|
||||
機械学習では入力サイズをすべて統一するのが一般的ですが、特に制約があるわけではなく、実際は同一のバッチ内で統一されていれば大丈夫です。NovelAIの言うbucketingは、あらかじめ教師データを、アスペクト比に応じた学習解像度ごとに分類しておくことを指しているようです。そしてバッチを各bucket内の画像で作成することで、バッチの画像サイズを統一します。
|
||||
|
||||
### トークン長の75から225への拡張
|
||||
Stable Diffusionでは最大75トークン(開始・終了を含むと77トークン)ですが、それを225トークンまで拡張します。
|
||||
ただしCLIPが受け付ける最大長は75トークンですので、225トークンの場合、単純に三分割してCLIPを呼び出してから結果を連結しています。
|
||||
|
||||
※これが望ましい実装なのかどうかはいまひとつわかりません。とりあえず動いてはいるようです。特に2.0では何も参考になる実装がないので独自に実装してあります。
|
||||
|
||||
※Automatic1111氏のWeb UIではカンマを意識して分割、といったこともしているようですが、私の場合はそこまでしておらず単純な分割です。
|
||||
|
||||
## 環境整備
|
||||
|
||||
このリポジトリの[README](./README-ja.md)を参照してください。
|
||||
|
||||
## 教師データの用意
|
||||
|
||||
学習させたい画像データを用意し、任意のフォルダに入れてください。リサイズ等の事前の準備は必要ありません。
|
||||
ただし学習解像度よりもサイズが小さい画像については、超解像などで品質を保ったまま拡大しておくことをお勧めします。
|
||||
|
||||
複数の教師データフォルダにも対応しています。前処理をそれぞれのフォルダに対して実行する形となります。
|
||||
|
||||
たとえば以下のように画像を格納します。
|
||||
|
||||

|
||||
|
||||
## 自動キャプショニング
|
||||
キャプションを使わずタグだけで学習する場合はスキップしてください。
|
||||
|
||||
また手動でキャプションを用意する場合、キャプションは教師データ画像と同じディレクトリに、同じファイル名、拡張子.caption等で用意してください。各ファイルは1行のみのテキストファイルとします。
|
||||
|
||||
### BLIPによるキャプショニング
|
||||
|
||||
最新版ではBLIPのダウンロード、重みのダウンロード、仮想環境の追加は不要になりました。そのままで動作します。
|
||||
|
||||
finetuneフォルダ内のmake_captions.pyを実行します。
|
||||
|
||||
```
|
||||
python finetune\make_captions.py --batch_size <バッチサイズ> <教師データフォルダ>
|
||||
```
|
||||
|
||||
バッチサイズ8、教師データを親フォルダのtrain_dataに置いた場合、以下のようになります。
|
||||
|
||||
```
|
||||
python finetune\make_captions.py --batch_size 8 ..\train_data
|
||||
```
|
||||
|
||||
キャプションファイルが教師データ画像と同じディレクトリに、同じファイル名、拡張子.captionで作成されます。
|
||||
|
||||
batch_sizeはGPUのVRAM容量に応じて増減してください。大きいほうが速くなります(VRAM 12GBでももう少し増やせると思います)。
|
||||
max_lengthオプションでキャプションの最大長を指定できます。デフォルトは75です。モデルをトークン長225で学習する場合には長くしても良いかもしれません。
|
||||
caption_extensionオプションでキャプションの拡張子を変更できます。デフォルトは.captionです(.txtにすると後述のDeepDanbooruと競合します)。
|
||||
|
||||
複数の教師データフォルダがある場合には、それぞれのフォルダに対して実行してください。
|
||||
|
||||
なお、推論にランダム性があるため、実行するたびに結果が変わります。固定する場合には--seedオプションで「--seed 42」のように乱数seedを指定してください。
|
||||
|
||||
その他のオプションは--helpでヘルプをご参照ください(パラメータの意味についてはドキュメントがまとまっていないようで、ソースを見るしかないようです)。
|
||||
|
||||
デフォルトでは拡張子.captionでキャプションファイルが生成されます。
|
||||
|
||||

|
||||
|
||||
たとえば以下のようなキャプションが付きます。
|
||||
|
||||

|
||||
|
||||
## DeepDanbooruによるタグ付け
|
||||
danbooruタグのタグ付け自体を行わない場合は「キャプションとタグ情報の前処理」に進んでください。
|
||||
|
||||
タグ付けはDeepDanbooruまたはWD14Taggerで行います。WD14Taggerのほうが精度が良いようです。WD14Taggerでタグ付けする場合は、次の章へ進んでください。
|
||||
|
||||
### 環境整備
|
||||
DeepDanbooru https://github.com/KichangKim/DeepDanbooru を作業フォルダにcloneしてくるか、zipをダウンロードして展開します。私はzipで展開しました。
|
||||
またDeepDanbooruのReleasesのページ https://github.com/KichangKim/DeepDanbooru/releases の「DeepDanbooru Pretrained Model v3-20211112-sgd-e28」のAssetsから、deepdanbooru-v3-20211112-sgd-e28.zipをダウンロードしてきてDeepDanbooruのフォルダに展開します。
|
||||
|
||||
以下からダウンロードします。Assetsをクリックして開き、そこからダウンロードします。
|
||||
|
||||

|
||||
|
||||
以下のようなこういうディレクトリ構造にしてください
|
||||
|
||||

|
||||
|
||||
Diffusersの環境に必要なライブラリをインストールします。DeepDanbooruのフォルダに移動してインストールします(実質的にはtensorflow-ioが追加されるだけだと思います)。
|
||||
|
||||
```
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
続いてDeepDanbooru自体をインストールします。
|
||||
|
||||
```
|
||||
pip install .
|
||||
```
|
||||
|
||||
以上でタグ付けの環境整備は完了です。
|
||||
|
||||
### タグ付けの実施
|
||||
DeepDanbooruのフォルダに移動し、deepdanbooruを実行してタグ付けを行います。
|
||||
|
||||
```
|
||||
deepdanbooru evaluate <教師データフォルダ> --project-path deepdanbooru-v3-20211112-sgd-e28 --allow-folder --save-txt
|
||||
```
|
||||
|
||||
教師データを親フォルダのtrain_dataに置いた場合、以下のようになります。
|
||||
|
||||
```
|
||||
deepdanbooru evaluate ../train_data --project-path deepdanbooru-v3-20211112-sgd-e28 --allow-folder --save-txt
|
||||
```
|
||||
|
||||
タグファイルが教師データ画像と同じディレクトリに、同じファイル名、拡張子.txtで作成されます。1件ずつ処理されるためわりと遅いです。
|
||||
|
||||
複数の教師データフォルダがある場合には、それぞれのフォルダに対して実行してください。
|
||||
|
||||
以下のように生成されます。
|
||||
|
||||

|
||||
|
||||
こんな感じにタグが付きます(すごい情報量……)。
|
||||
|
||||

|
||||
|
||||
## WD14Taggerによるタグ付け
|
||||
DeepDanbooruの代わりにWD14Taggerを用いる手順です。
|
||||
|
||||
Automatic1111氏のWebUIで使用しているtaggerを利用します。こちらのgithubページ(https://github.com/toriato/stable-diffusion-webui-wd14-tagger#mrsmilingwolfs-model-aka-waifu-diffusion-14-tagger )の情報を参考にさせていただきました。
|
||||
|
||||
最初の環境整備で必要なモジュールはインストール済みです。また重みはHugging Faceから自動的にダウンロードしてきます。
|
||||
|
||||
### タグ付けの実施
|
||||
スクリプトを実行してタグ付けを行います。
|
||||
```
|
||||
python tag_images_by_wd14_tagger.py --batch_size <バッチサイズ> <教師データフォルダ>
|
||||
```
|
||||
|
||||
教師データを親フォルダのtrain_dataに置いた場合、以下のようになります。
|
||||
```
|
||||
python tag_images_by_wd14_tagger.py --batch_size 4 ..\train_data
|
||||
```
|
||||
|
||||
初回起動時にはモデルファイルがwd14_tagger_modelフォルダに自動的にダウンロードされます(フォルダはオプションで変えられます)。以下のようになります。
|
||||
|
||||

|
||||
|
||||
タグファイルが教師データ画像と同じディレクトリに、同じファイル名、拡張子.txtで作成されます。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
threshオプションで、判定されたタグのconfidence(確信度)がいくつ以上でタグをつけるかが指定できます。デフォルトはWD14Taggerのサンプルと同じ0.35です。値を下げるとより多くのタグが付与されますが、精度は下がります。
|
||||
batch_sizeはGPUのVRAM容量に応じて増減してください。大きいほうが速くなります(VRAM 12GBでももう少し増やせると思います)。caption_extensionオプションでタグファイルの拡張子を変更できます。デフォルトは.txtです。
|
||||
model_dirオプションでモデルの保存先フォルダを指定できます。
|
||||
またforce_downloadオプションを指定すると保存先フォルダがあってもモデルを再ダウンロードします。
|
||||
|
||||
複数の教師データフォルダがある場合には、それぞれのフォルダに対して実行してください。
|
||||
|
||||
## キャプションとタグ情報の前処理
|
||||
|
||||
スクリプトから処理しやすいようにキャプションとタグをメタデータとしてひとつのファイルにまとめます。
|
||||
|
||||
### キャプションの前処理
|
||||
|
||||
キャプションをメタデータに入れるには、作業フォルダ内で以下を実行してください(キャプションを学習に使わない場合は実行不要です)(実際は1行で記述します、以下同様)。
|
||||
|
||||
```
|
||||
python merge_captions_to_metadata.py <教師データフォルダ>
|
||||
--in_json <読み込むメタデータファイル名>
|
||||
<メタデータファイル名>
|
||||
```
|
||||
|
||||
メタデータファイル名は任意の名前です。
|
||||
教師データがtrain_data、読み込むメタデータファイルなし、メタデータファイルがmeta_cap.jsonの場合、以下のようになります。
|
||||
|
||||
```
|
||||
python merge_captions_to_metadata.py train_data meta_cap.json
|
||||
```
|
||||
|
||||
caption_extensionオプションでキャプションの拡張子を指定できます。
|
||||
|
||||
複数の教師データフォルダがある場合には、full_path引数を指定してください(メタデータにフルパスで情報を持つようになります)。そして、それぞれのフォルダに対して実行してください。
|
||||
|
||||
```
|
||||
python merge_captions_to_metadata.py --full_path
|
||||
train_data1 meta_cap1.json
|
||||
python merge_captions_to_metadata.py --full_path --in_json meta_cap1.json
|
||||
train_data2 meta_cap2.json
|
||||
```
|
||||
|
||||
in_jsonを省略すると書き込み先メタデータファイルがあるとそこから読み込み、そこに上書きします。
|
||||
|
||||
__※in_jsonオプションと書き込み先を都度書き換えて、別のメタデータファイルへ書き出すようにすると安全です。__
|
||||
|
||||
### タグの前処理
|
||||
|
||||
同様にタグもメタデータにまとめます(タグを学習に使わない場合は実行不要です)。
|
||||
```
|
||||
python merge_dd_tags_to_metadata.py <教師データフォルダ>
|
||||
--in_json <読み込むメタデータファイル名>
|
||||
<書き込むメタデータファイル名>
|
||||
```
|
||||
|
||||
先と同じディレクトリ構成で、meta_cap.jsonを読み、meta_cap_dd.jsonに書きだす場合、以下となります。
|
||||
```
|
||||
python merge_dd_tags_to_metadata.py train_data --in_json meta_cap.json meta_cap_dd.json
|
||||
```
|
||||
|
||||
複数の教師データフォルダがある場合には、full_path引数を指定してください。そして、それぞれのフォルダに対して実行してください。
|
||||
|
||||
```
|
||||
python merge_dd_tags_to_metadata.py --full_path --in_json meta_cap2.json
|
||||
train_data1 meta_cap_dd1.json
|
||||
python merge_dd_tags_to_metadata.py --full_path --in_json meta_cap_dd1.json
|
||||
train_data2 meta_cap_dd2.json
|
||||
```
|
||||
|
||||
in_jsonを省略すると書き込み先メタデータファイルがあるとそこから読み込み、そこに上書きします。
|
||||
|
||||
__※in_jsonオプションと書き込み先を都度書き換えて、別のメタデータファイルへ書き出すようにすると安全です。__
|
||||
|
||||
### キャプションとタグのクリーニング
|
||||
ここまででメタデータファイルにキャプションとDeepDanbooruのタグがまとめられています。ただ自動キャプショニングにしたキャプションは表記ゆれなどがあり微妙(※)ですし、タグにはアンダースコアが含まれていたりratingが付いていたりしますので(DeepDanbooruの場合)、エディタの置換機能などを用いてキャプションとタグのクリーニングをしたほうがいいでしょう。
|
||||
|
||||
※たとえばアニメ絵の少女を学習する場合、キャプションにはgirl/girls/woman/womenなどのばらつきがあります。また「anime girl」なども単に「girl」としたほうが適切かもしれません。
|
||||
|
||||
クリーニング用のスクリプトが用意してありますので、スクリプトの内容を状況に応じて編集してお使いください。
|
||||
|
||||
(教師データフォルダの指定は不要になりました。メタデータ内の全データをクリーニングします。)
|
||||
|
||||
```
|
||||
python clean_captions_and_tags.py <読み込むメタデータファイル名> <書き込むメタデータファイル名>
|
||||
```
|
||||
|
||||
--in_jsonは付きませんのでご注意ください。たとえば次のようになります。
|
||||
|
||||
```
|
||||
python clean_captions_and_tags.py meta_cap_dd.json meta_clean.json
|
||||
```
|
||||
|
||||
以上でキャプションとタグの前処理は完了です。
|
||||
|
||||
## latentsの事前取得
|
||||
|
||||
学習を高速に進めるためあらかじめ画像の潜在表現を取得しディスクに保存しておきます。あわせてbucketing(教師データをアスペクト比に応じて分類する)を行います。
|
||||
|
||||
作業フォルダで以下のように入力してください。
|
||||
```
|
||||
python prepare_buckets_latents.py <教師データフォルダ>
|
||||
<読み込むメタデータファイル名> <書き込むメタデータファイル名>
|
||||
<fine tuningするモデル名またはcheckpoint>
|
||||
--batch_size <バッチサイズ>
|
||||
--max_resolution <解像度 幅,高さ>
|
||||
--mixed_precision <精度>
|
||||
```
|
||||
|
||||
モデルがmodel.ckpt、バッチサイズ4、学習解像度は512\*512、精度no(float32)で、meta_clean.jsonからメタデータを読み込み、meta_lat.jsonに書き込む場合、以下のようになります。
|
||||
|
||||
```
|
||||
python prepare_buckets_latents.py
|
||||
train_data meta_clean.json meta_lat.json model.ckpt
|
||||
--batch_size 4 --max_resolution 512,512 --mixed_precision no
|
||||
```
|
||||
|
||||
教師データフォルダにnumpyのnpz形式でlatentsが保存されます。
|
||||
|
||||
Stable Diffusion 2.0のモデルを読み込む場合は--v2オプションを指定してください(--v_parameterizationは不要です)。
|
||||
|
||||
解像度の最小サイズを--min_bucket_resoオプションで、最大サイズを--max_bucket_resoで指定できます。デフォルトはそれぞれ256、1024です。たとえば最小サイズに384を指定すると、256\*1024や320\*768などの解像度は使わなくなります。
|
||||
解像度を768\*768のように大きくした場合、最大サイズに1280などを指定すると良いでしょう。
|
||||
|
||||
--flip_augオプションを指定すると左右反転のaugmentation(データ拡張)を行います。疑似的にデータ量を二倍に増やすことができますが、データが左右対称でない場合に指定すると(例えばキャラクタの外見、髪型など)学習がうまく行かなくなります。
|
||||
(反転した画像についてもlatentsを取得し、\*\_flip.npzファイルを保存する単純な実装です。fline_tune.pyには特にオプション指定は必要ありません。\_flip付きのファイルがある場合、flip付き・なしのファイルを、ランダムに読み込みます。)
|
||||
|
||||
バッチサイズはVRAM 12GBでももう少し増やせるかもしれません。
|
||||
解像度は64で割り切れる数字で、"幅,高さ"で指定します。解像度はfine tuning時のメモリサイズに直結します。VRAM 12GBでは512,512が限界と思われます(※)。16GBなら512,704や512,768まで上げられるかもしれません。なお256,256等にしてもVRAM 8GBでは厳しいようです(パラメータやoptimizerなどは解像度に関係せず一定のメモリが必要なため)。
|
||||
|
||||
※batch size 1の学習で12GB VRAM、640,640で動いたとの報告もありました。
|
||||
|
||||
以下のようにbucketingの結果が表示されます。
|
||||
|
||||

|
||||
|
||||
複数の教師データフォルダがある場合には、full_path引数を指定してください。そして、それぞれのフォルダに対して実行してください。
|
||||
```
|
||||
python prepare_buckets_latents.py --full_path
|
||||
train_data1 meta_clean.json meta_lat1.json model.ckpt
|
||||
--batch_size 4 --max_resolution 512,512 --mixed_precision no
|
||||
|
||||
python prepare_buckets_latents.py --full_path
|
||||
train_data2 meta_lat1.json meta_lat2.json model.ckpt
|
||||
--batch_size 4 --max_resolution 512,512 --mixed_precision no
|
||||
|
||||
```
|
||||
読み込み元と書き込み先を同じにすることも可能ですが別々の方が安全です。
|
||||
|
||||
__※引数を都度書き換えて、別のメタデータファイルに書き込むと安全です。__
|
||||
|
||||
|
||||
## 学習の実行
|
||||
たとえば以下のように実行します。以下は省メモリ化のための設定です。
|
||||
```
|
||||
accelerate launch --num_cpu_threads_per_process 8 fine_tune.py
|
||||
--pretrained_model_name_or_path=model.ckpt
|
||||
--in_json meta_lat.json
|
||||
--train_data_dir=train_data
|
||||
--output_dir=fine_tuned
|
||||
--shuffle_caption
|
||||
--train_batch_size=1 --learning_rate=5e-6 --max_train_steps=10000
|
||||
--use_8bit_adam --xformers --gradient_checkpointing
|
||||
--mixed_precision=bf16
|
||||
--save_every_n_epochs=4
|
||||
```
|
||||
|
||||
accelerateのnum_cpu_threads_per_processにはCPUのコア数を指定するとよいようです。
|
||||
|
||||
pretrained_model_name_or_pathに学習対象のモデルを指定します(Stable DiffusionのcheckpointかDiffusersのモデル)。Stable Diffusionのcheckpointは.ckptと.safetensorsに対応しています(拡張子で自動判定)。
|
||||
|
||||
in_jsonにlatentをキャッシュしたときのメタデータファイルを指定します。
|
||||
|
||||
train_data_dirに教師データのフォルダを、output_dirに学習後のモデルの出力先フォルダを指定します。
|
||||
|
||||
shuffle_captionを指定すると、キャプション、タグをカンマ区切りされた単位でシャッフルして学習します(Waifu Diffusion v1.3で行っている手法です)。
|
||||
(先頭のトークンのいくつかをシャッフルせずに固定できます。その他のオプションのkeep_tokensをご覧ください。)
|
||||
|
||||
train_batch_sizeにバッチサイズを指定します。VRAM 12GBでは1か2程度を指定してください。解像度によっても指定可能な数は変わってきます。
|
||||
学習に使用される実際のデータ量は「バッチサイズ×ステップ数」です。バッチサイズを増やした時には、それに応じてステップ数を下げることが可能です。
|
||||
|
||||
learning_rateに学習率を指定します。たとえばWaifu Diffusion v1.3は5e-6のようです。
|
||||
max_train_stepsにステップ数を指定します。
|
||||
|
||||
use_8bit_adamを指定すると8-bit Adam Optimizerを使用します。省メモリ化、高速化されますが精度は下がる可能性があります。
|
||||
|
||||
xformersを指定するとCrossAttentionを置換して省メモリ化、高速化します。
|
||||
※11/9時点ではfloat32の学習ではxformersがエラーになるため、bf16/fp16を使うか、代わりにmem_eff_attnを指定して省メモリ版CrossAttentionを使ってください(速度はxformersに劣ります)。
|
||||
|
||||
gradient_checkpointingで勾配の途中保存を有効にします。速度は遅くなりますが使用メモリ量が減ります。
|
||||
|
||||
mixed_precisionで混合精度を使うか否かを指定します。"fp16"または"bf16"を指定すると省メモリになりますが精度は劣ります。
|
||||
"fp16"と"bf16"は使用メモリ量はほぼ同じで、bf16の方が学習結果は良くなるとの話もあります(試した範囲ではあまり違いは感じられませんでした)。
|
||||
"no"を指定すると使用しません(float32になります)。
|
||||
|
||||
※bf16で学習したcheckpointをAUTOMATIC1111氏のWeb UIで読み込むとエラーになるようです。これはデータ型のbfloat16がWeb UIのモデルsafety checkerでエラーとなるためのようです。save_precisionオプションを指定してfp16またはfloat32形式で保存してください。またはsafetensors形式で保管しても良さそうです。
|
||||
|
||||
save_every_n_epochsを指定するとそのエポックだけ経過するたびに学習中のモデルを保存します。
|
||||
|
||||
### Stable Diffusion 2.0対応
|
||||
Hugging Faceのstable-diffusion-2-baseを使う場合は--v2オプションを、stable-diffusion-2または768-v-ema.ckptを使う場合は--v2と--v_parameterizationの両方のオプションを指定してください。
|
||||
|
||||
### メモリに余裕がある場合に精度や速度を上げる
|
||||
まずgradient_checkpointingを外すと速度が上がります。ただし設定できるバッチサイズが減りますので、精度と速度のバランスを見ながら設定してください。
|
||||
|
||||
バッチサイズを増やすと速度、精度が上がります。メモリが足りる範囲で、1データ当たりの速度を確認しながら増やしてください(メモリがぎりぎりになるとかえって速度が落ちることがあります)。
|
||||
|
||||
### 使用するCLIP出力の変更
|
||||
clip_skipオプションに2を指定すると、後ろから二番目の層の出力を用います。1またはオプション省略時は最後の層を用います。
|
||||
学習したモデルはAutomatic1111氏のWeb UIで推論できるはずです。
|
||||
|
||||
※SD2.0はデフォルトで後ろから二番目の層を使うため、SD2.0の学習では指定しないでください。
|
||||
|
||||
学習対象のモデルがもともと二番目の層を使うように学習されている場合は、2を指定するとよいでしょう。
|
||||
|
||||
そうではなく最後の層を使用していた場合はモデル全体がそれを前提に学習されています。そのため改めて二番目の層を使用して学習すると、望ましい学習結果を得るにはある程度の枚数の教師データ、長めの学習が必要になるかもしれません。
|
||||
|
||||
### トークン長の拡張
|
||||
max_token_lengthに150または225を指定することでトークン長を拡張して学習できます。
|
||||
学習したモデルはAutomatic1111氏のWeb UIで推論できるはずです。
|
||||
|
||||
clip_skipと同様に、モデルの学習状態と異なる長さで学習するには、ある程度の教師データ枚数、長めの学習時間が必要になると思われます。
|
||||
|
||||
### 学習ログの保存
|
||||
logging_dirオプションにログ保存先フォルダを指定してください。TensorBoard形式のログが保存されます。
|
||||
|
||||
たとえば--logging_dir=logsと指定すると、作業フォルダにlogsフォルダが作成され、その中の日時フォルダにログが保存されます。
|
||||
また--log_prefixオプションを指定すると、日時の前に指定した文字列が追加されます。「--logging_dir=logs --log_prefix=fine_tune_style1」などとして識別用にお使いください。
|
||||
|
||||
TensorBoardでログを確認するには、別のコマンドプロンプトを開き、作業フォルダで以下のように入力します(tensorboardはDiffusersのインストール時にあわせてインストールされると思いますが、もし入っていないならpip install tensorboardで入れてください)。
|
||||
```
|
||||
tensorboard --logdir=logs
|
||||
```
|
||||
|
||||
### Hypernetworkの学習
|
||||
別の記事で解説予定です。
|
||||
|
||||
### 勾配をfp16とした学習(実験的機能)
|
||||
full_fp16オプションを指定すると勾配を通常のfloat32からfloat16(fp16)に変更して学習します(mixed precisionではなく完全なfp16学習になるようです)。これによりSD1.xの512*512サイズでは8GB未満、SD2.xの512*512サイズで12GB未満のVRAM使用量で学習できるようです。
|
||||
|
||||
あらかじめaccelerate configでfp16を指定し、オプションでmixed_precision="fp16"としてください(bf16では動作しません)。
|
||||
|
||||
メモリ使用量を最小化するためには、xformers、use_8bit_adam、gradient_checkpointingの各オプションを指定し、train_batch_sizeを1としてください。
|
||||
(余裕があるようならtrain_batch_sizeを段階的に増やすと若干精度が上がるはずです。)
|
||||
|
||||
PyTorchのソースにパッチを当てて無理やり実現しています(PyTorch 1.12.1と1.13.0で確認)。精度はかなり落ちますし、途中で学習失敗する確率も高くなります。学習率やステップ数の設定もシビアなようです。それらを認識したうえで自己責任でお使いください。
|
||||
|
||||
### その他のオプション
|
||||
|
||||
#### keep_tokens
|
||||
数値を指定するとキャプションの先頭から、指定した数だけのトークン(カンマ区切りの文字列)をシャッフルせず固定します。
|
||||
|
||||
キャプションとタグが両方ある場合、学習時のプロンプトは「キャプション,タグ1,タグ2……」のように連結されますので、「--keep_tokens=1」とすれば、学習時にキャプションが必ず先頭に来るようになります。
|
||||
|
||||
#### dataset_repeats
|
||||
データセットの枚数が極端に少ない場合、epochがすぐに終わってしまうため(epochの区切りで少し時間が掛かります)、数値を指定してデータを何倍かしてepochを長めにしてください。
|
||||
|
||||
#### train_text_encoder
|
||||
Text Encoderも学習対象とします。メモリ使用量が若干増加します。
|
||||
|
||||
通常のfine tuningではText Encoderは学習対象としませんが(恐らくText Encoderの出力に従うようにU-Netを学習するため)、学習データ数が少ない場合には、DreamBoothのようにText Encoder側に学習させるのも有効的なようです。
|
||||
|
||||
#### save_precision
|
||||
checkpoint保存時のデータ形式をfloat、fp16、bf16から指定できます(未指定時は学習中のデータ形式と同じ)。ディスク容量が節約できますがモデルによる生成結果は変わってきます。またfloatやfp16を指定すると、1111氏のWeb UIでも読めるようになるはずです。
|
||||
|
||||
※VAEについては元のcheckpointのデータ形式のままになりますので、fp16でもモデルサイズが2GB強まで小さくならない場合があります。
|
||||
|
||||
#### save_model_as
|
||||
モデルの保存形式を指定します。ckpt、safetensors、diffusers、diffusers_safetensorsのいずれかを指定してください。
|
||||
|
||||
Stable Diffusion形式(ckptまたはsafetensors)を読み込み、Diffusers形式で保存する場合、不足する情報はHugging Faceからv1.5またはv2.1の情報を落としてきて補完します。
|
||||
|
||||
#### use_safetensors
|
||||
このオプションを指定するとsafetensors形式でcheckpointを保存します。保存形式はデフォルト(読み込んだ形式と同じ)になります。
|
||||
|
||||
#### save_stateとresume
|
||||
save_stateオプションで、途中保存時および最終保存時に、checkpointに加えてoptimizer等の学習状態をフォルダに保存します。これにより中断してから学習再開したときの精度低下が避けられます(optimizerは状態を持ちながら最適化をしていくため、その状態がリセットされると再び初期状態から最適化を行わなくてはなりません)。なお、Accelerateの仕様でステップ数は保存されません。
|
||||
|
||||
スクリプト起動時、resumeオプションで状態の保存されたフォルダを指定すると再開できます。
|
||||
|
||||
学習状態は一回の保存あたり5GB程度になりますのでディスク容量にご注意ください。
|
||||
|
||||
#### gradient_accumulation_steps
|
||||
指定したステップ数だけまとめて勾配を更新します。バッチサイズを増やすのと同様の効果がありますが、メモリを若干消費します。
|
||||
|
||||
※Accelerateの仕様で学習モデルが複数の場合には対応していないとのことですので、Text Encoderを学習対象にして、このオプションに2以上の値を指定するとエラーになるかもしれません。
|
||||
|
||||
#### lr_scheduler / lr_warmup_steps
|
||||
lr_schedulerオプションで学習率のスケジューラをlinear, cosine, cosine_with_restarts, polynomial, constant, constant_with_warmupから選べます。デフォルトはconstantです。
|
||||
|
||||
lr_warmup_stepsでスケジューラのウォームアップ(だんだん学習率を変えていく)ステップ数を指定できます。詳細については各自お調べください。
|
||||
|
||||
#### diffusers_xformers
|
||||
スクリプト独自のxformers置換機能ではなくDiffusersのxformers機能を利用します。Hypernetworkの学習はできなくなります。
|
||||
231
finetune_gui.py
231
finetune_gui.py
@ -11,6 +11,8 @@ from library.common_gui import (
|
||||
get_file_path,
|
||||
get_any_file_path,
|
||||
get_saveasfile_path,
|
||||
save_inference_file,
|
||||
set_pretrained_model_name_or_path_input,
|
||||
)
|
||||
from library.utilities import utilities_tab
|
||||
|
||||
@ -59,7 +61,15 @@ def save_configuration(
|
||||
clip_skip,
|
||||
save_state,
|
||||
resume,
|
||||
gradient_checkpointing,
|
||||
gradient_accumulation_steps,
|
||||
mem_eff_attn,
|
||||
shuffle_caption,
|
||||
output_name,
|
||||
):
|
||||
# Get list of function parameters and values
|
||||
parameters = list(locals().items())
|
||||
|
||||
original_file_path = file_path
|
||||
|
||||
save_as_bool = True if save_as.get('label') == 'True' else False
|
||||
@ -79,47 +89,18 @@ def save_configuration(
|
||||
|
||||
# Return the values of the variables as a dictionary
|
||||
variables = {
|
||||
'pretrained_model_name_or_path': pretrained_model_name_or_path,
|
||||
'v2': v2,
|
||||
'v_parameterization': v_parameterization,
|
||||
'train_dir': train_dir,
|
||||
'image_folder': image_folder,
|
||||
'output_dir': output_dir,
|
||||
'logging_dir': logging_dir,
|
||||
'max_resolution': max_resolution,
|
||||
'min_bucket_reso': min_bucket_reso,
|
||||
'max_bucket_reso': max_bucket_reso,
|
||||
'batch_size': batch_size,
|
||||
'flip_aug': flip_aug,
|
||||
'caption_metadata_filename': caption_metadata_filename,
|
||||
'latent_metadata_filename': latent_metadata_filename,
|
||||
'full_path': full_path,
|
||||
'learning_rate': learning_rate,
|
||||
'lr_scheduler': lr_scheduler,
|
||||
'lr_warmup': lr_warmup,
|
||||
'dataset_repeats': dataset_repeats,
|
||||
'train_batch_size': train_batch_size,
|
||||
'epoch': epoch,
|
||||
'save_every_n_epochs': save_every_n_epochs,
|
||||
'mixed_precision': mixed_precision,
|
||||
'save_precision': save_precision,
|
||||
'seed': seed,
|
||||
'num_cpu_threads_per_process': num_cpu_threads_per_process,
|
||||
'train_text_encoder': train_text_encoder,
|
||||
'create_buckets': create_buckets,
|
||||
'create_caption': create_caption,
|
||||
'save_model_as': save_model_as,
|
||||
'caption_extension': caption_extension,
|
||||
'use_8bit_adam': use_8bit_adam,
|
||||
'xformers': xformers,
|
||||
'clip_skip': clip_skip,
|
||||
'save_state': save_state,
|
||||
'resume': resume,
|
||||
name: value
|
||||
for name, value in parameters # locals().items()
|
||||
if name
|
||||
not in [
|
||||
'file_path',
|
||||
'save_as',
|
||||
]
|
||||
}
|
||||
|
||||
# Save the data to the selected file
|
||||
with open(file_path, 'w') as file:
|
||||
json.dump(variables, file)
|
||||
json.dump(variables, file, indent=2)
|
||||
|
||||
return file_path
|
||||
|
||||
@ -162,7 +143,15 @@ def open_config_file(
|
||||
clip_skip,
|
||||
save_state,
|
||||
resume,
|
||||
gradient_checkpointing,
|
||||
gradient_accumulation_steps,
|
||||
mem_eff_attn,
|
||||
shuffle_caption,
|
||||
output_name,
|
||||
):
|
||||
# Get list of function parameters and values
|
||||
parameters = list(locals().items())
|
||||
|
||||
original_file_path = file_path
|
||||
file_path = get_file_path(file_path)
|
||||
|
||||
@ -170,55 +159,18 @@ def open_config_file(
|
||||
print(f'Loading config file {file_path}')
|
||||
# load variables from JSON file
|
||||
with open(file_path, 'r') as f:
|
||||
my_data = json.load(f)
|
||||
my_data_ft = json.load(f)
|
||||
else:
|
||||
file_path = original_file_path # In case a file_path was provided and the user decide to cancel the open action
|
||||
my_data = {}
|
||||
|
||||
# Return the values of the variables as a dictionary
|
||||
return (
|
||||
file_path,
|
||||
my_data.get(
|
||||
'pretrained_model_name_or_path', pretrained_model_name_or_path
|
||||
),
|
||||
my_data.get('v2', v2),
|
||||
my_data.get('v_parameterization', v_parameterization),
|
||||
my_data.get('train_dir', train_dir),
|
||||
my_data.get('image_folder', image_folder),
|
||||
my_data.get('output_dir', output_dir),
|
||||
my_data.get('logging_dir', logging_dir),
|
||||
my_data.get('max_resolution', max_resolution),
|
||||
my_data.get('min_bucket_reso', min_bucket_reso),
|
||||
my_data.get('max_bucket_reso', max_bucket_reso),
|
||||
my_data.get('batch_size', batch_size),
|
||||
my_data.get('flip_aug', flip_aug),
|
||||
my_data.get('caption_metadata_filename', caption_metadata_filename),
|
||||
my_data.get('latent_metadata_filename', latent_metadata_filename),
|
||||
my_data.get('full_path', full_path),
|
||||
my_data.get('learning_rate', learning_rate),
|
||||
my_data.get('lr_scheduler', lr_scheduler),
|
||||
my_data.get('lr_warmup', lr_warmup),
|
||||
my_data.get('dataset_repeats', dataset_repeats),
|
||||
my_data.get('train_batch_size', train_batch_size),
|
||||
my_data.get('epoch', epoch),
|
||||
my_data.get('save_every_n_epochs', save_every_n_epochs),
|
||||
my_data.get('mixed_precision', mixed_precision),
|
||||
my_data.get('save_precision', save_precision),
|
||||
my_data.get('seed', seed),
|
||||
my_data.get(
|
||||
'num_cpu_threads_per_process', num_cpu_threads_per_process
|
||||
),
|
||||
my_data.get('train_text_encoder', train_text_encoder),
|
||||
my_data.get('create_buckets', create_buckets),
|
||||
my_data.get('create_caption', create_caption),
|
||||
my_data.get('save_model_as', save_model_as),
|
||||
my_data.get('caption_extension', caption_extension),
|
||||
my_data.get('use_8bit_adam', use_8bit_adam),
|
||||
my_data.get('xformers', xformers),
|
||||
my_data.get('clip_skip', clip_skip),
|
||||
my_data.get('save_state', save_state),
|
||||
my_data.get('resume', resume),
|
||||
)
|
||||
my_data_ft = {}
|
||||
|
||||
values = [file_path]
|
||||
for key, value in parameters:
|
||||
# Set the value in the dictionary to the corresponding value in `my_data_ft`, or the default value if not found
|
||||
if not key in ['file_path']:
|
||||
values.append(my_data_ft.get(key, value))
|
||||
# print(values)
|
||||
return tuple(values)
|
||||
|
||||
|
||||
def train_model(
|
||||
@ -258,22 +210,12 @@ def train_model(
|
||||
clip_skip,
|
||||
save_state,
|
||||
resume,
|
||||
gradient_checkpointing,
|
||||
gradient_accumulation_steps,
|
||||
mem_eff_attn,
|
||||
shuffle_caption,
|
||||
output_name,
|
||||
):
|
||||
def save_inference_file(output_dir, v2, v_parameterization):
|
||||
# Copy inference model for v2 if required
|
||||
if v2 and v_parameterization:
|
||||
print(f'Saving v2-inference-v.yaml as {output_dir}/last.yaml')
|
||||
shutil.copy(
|
||||
f'./v2_inference/v2-inference-v.yaml',
|
||||
f'{output_dir}/last.yaml',
|
||||
)
|
||||
elif v2:
|
||||
print(f'Saving v2-inference.yaml as {output_dir}/last.yaml')
|
||||
shutil.copy(
|
||||
f'./v2_inference/v2-inference.yaml',
|
||||
f'{output_dir}/last.yaml',
|
||||
)
|
||||
|
||||
# create caption json file
|
||||
if generate_caption_database:
|
||||
if not os.path.exists(train_dir):
|
||||
@ -353,6 +295,12 @@ def train_model(
|
||||
run_cmd += f' --use_8bit_adam'
|
||||
if xformers:
|
||||
run_cmd += f' --xformers'
|
||||
if gradient_checkpointing:
|
||||
run_cmd += ' --gradient_checkpointing'
|
||||
if mem_eff_attn:
|
||||
run_cmd += ' --mem_eff_attn'
|
||||
if shuffle_caption:
|
||||
run_cmd += ' --shuffle_caption'
|
||||
run_cmd += (
|
||||
f' --pretrained_model_name_or_path="{pretrained_model_name_or_path}"'
|
||||
)
|
||||
@ -375,72 +323,25 @@ def train_model(
|
||||
run_cmd += f' --save_model_as={save_model_as}'
|
||||
if int(clip_skip) > 1:
|
||||
run_cmd += f' --clip_skip={str(clip_skip)}'
|
||||
if int(gradient_accumulation_steps) > 1:
|
||||
run_cmd += f' --gradient_accumulation_steps={int(gradient_accumulation_steps)}'
|
||||
if save_state:
|
||||
run_cmd += ' --save_state'
|
||||
if not resume == '':
|
||||
run_cmd += f' --resume={resume}'
|
||||
if not output_name == '':
|
||||
run_cmd += f' --output_name="{output_name}"'
|
||||
|
||||
print(run_cmd)
|
||||
# Run the command
|
||||
subprocess.run(run_cmd)
|
||||
|
||||
# check if output_dir/last is a folder... therefore it is a diffuser model
|
||||
last_dir = pathlib.Path(f'{output_dir}/last')
|
||||
last_dir = pathlib.Path(f'{output_dir}/{output_name}')
|
||||
|
||||
if not last_dir.is_dir():
|
||||
# Copy inference model for v2 if required
|
||||
save_inference_file(output_dir, v2, v_parameterization)
|
||||
|
||||
|
||||
def set_pretrained_model_name_or_path_input(value, v2, v_parameterization):
|
||||
# define a list of substrings to search for
|
||||
substrings_v2 = [
|
||||
'stabilityai/stable-diffusion-2-1-base',
|
||||
'stabilityai/stable-diffusion-2-base',
|
||||
]
|
||||
|
||||
# check if $v2 and $v_parameterization are empty and if $pretrained_model_name_or_path contains any of the substrings in the v2 list
|
||||
if str(value) in substrings_v2:
|
||||
print('SD v2 model detected. Setting --v2 parameter')
|
||||
v2 = True
|
||||
v_parameterization = False
|
||||
|
||||
return value, v2, v_parameterization
|
||||
|
||||
# define a list of substrings to search for v-objective
|
||||
substrings_v_parameterization = [
|
||||
'stabilityai/stable-diffusion-2-1',
|
||||
'stabilityai/stable-diffusion-2',
|
||||
]
|
||||
|
||||
# check if $v2 and $v_parameterization are empty and if $pretrained_model_name_or_path contains any of the substrings in the v_parameterization list
|
||||
if str(value) in substrings_v_parameterization:
|
||||
print(
|
||||
'SD v2 v_parameterization detected. Setting --v2 parameter and --v_parameterization'
|
||||
)
|
||||
v2 = True
|
||||
v_parameterization = True
|
||||
|
||||
return value, v2, v_parameterization
|
||||
|
||||
# define a list of substrings to v1.x
|
||||
substrings_v1_model = [
|
||||
'CompVis/stable-diffusion-v1-4',
|
||||
'runwayml/stable-diffusion-v1-5',
|
||||
]
|
||||
|
||||
if str(value) in substrings_v1_model:
|
||||
v2 = False
|
||||
v_parameterization = False
|
||||
|
||||
return value, v2, v_parameterization
|
||||
|
||||
if value == 'custom':
|
||||
value = ''
|
||||
v2 = False
|
||||
v_parameterization = False
|
||||
|
||||
return value, v2, v_parameterization
|
||||
save_inference_file(output_dir, v2, v_parameterization, output_name)
|
||||
|
||||
|
||||
def remove_doublequote(file_path):
|
||||
@ -582,7 +483,7 @@ def finetune_tab():
|
||||
)
|
||||
with gr.Row():
|
||||
output_dir_input = gr.Textbox(
|
||||
label='Output folder',
|
||||
label='Model output folder',
|
||||
placeholder='folder where the model will be saved',
|
||||
)
|
||||
output_dir_input_folder = gr.Button(
|
||||
@ -602,6 +503,13 @@ def finetune_tab():
|
||||
logging_dir_input_folder.click(
|
||||
get_folder_path, outputs=logging_dir_input
|
||||
)
|
||||
with gr.Row():
|
||||
output_name = gr.Textbox(
|
||||
label='Model output name',
|
||||
placeholder='Name of the model to output',
|
||||
value='last',
|
||||
interactive=True,
|
||||
)
|
||||
train_dir_input.change(
|
||||
remove_doublequote,
|
||||
inputs=[train_dir_input],
|
||||
@ -712,6 +620,12 @@ def finetune_tab():
|
||||
clip_skip = gr.Slider(
|
||||
label='Clip skip', value='1', minimum=1, maximum=12, step=1
|
||||
)
|
||||
mem_eff_attn = gr.Checkbox(
|
||||
label='Memory efficient attention', value=False
|
||||
)
|
||||
shuffle_caption = gr.Checkbox(
|
||||
label='Shuffle caption', value=False
|
||||
)
|
||||
with gr.Row():
|
||||
save_state = gr.Checkbox(
|
||||
label='Save training state', value=False
|
||||
@ -722,6 +636,12 @@ def finetune_tab():
|
||||
)
|
||||
resume_button = gr.Button('📂', elem_id='open_folder_small')
|
||||
resume_button.click(get_folder_path, outputs=resume)
|
||||
gradient_checkpointing = gr.Checkbox(
|
||||
label='Gradient checkpointing', value=False
|
||||
)
|
||||
gradient_accumulation_steps = gr.Number(
|
||||
label='Gradient accumulate steps', value='1'
|
||||
)
|
||||
with gr.Box():
|
||||
with gr.Row():
|
||||
create_caption = gr.Checkbox(
|
||||
@ -770,6 +690,11 @@ def finetune_tab():
|
||||
clip_skip,
|
||||
save_state,
|
||||
resume,
|
||||
gradient_checkpointing,
|
||||
gradient_accumulation_steps,
|
||||
mem_eff_attn,
|
||||
shuffle_caption,
|
||||
output_name,
|
||||
]
|
||||
|
||||
button_run.click(train_model, inputs=settings_list)
|
||||
|
||||
@ -2,6 +2,7 @@ from tkinter import filedialog, Tk
|
||||
import os
|
||||
import gradio as gr
|
||||
from easygui import msgbox
|
||||
import shutil
|
||||
|
||||
def get_dir_and_file(file_path):
|
||||
dir_path, file_name = os.path.split(file_path)
|
||||
@ -183,4 +184,81 @@ def color_aug_changed(color_aug):
|
||||
msgbox('Disabling "Cache latent" because "Color augmentation" has been selected...')
|
||||
return gr.Checkbox.update(value=False, interactive=False)
|
||||
else:
|
||||
return gr.Checkbox.update(value=True, interactive=True)
|
||||
return gr.Checkbox.update(value=True, interactive=True)
|
||||
|
||||
def save_inference_file(output_dir, v2, v_parameterization, output_name):
|
||||
# List all files in the directory
|
||||
files = os.listdir(output_dir)
|
||||
|
||||
# Iterate over the list of files
|
||||
for file in files:
|
||||
# Check if the file starts with the value of output_name
|
||||
if file.startswith(output_name):
|
||||
# Check if it is a file or a directory
|
||||
if os.path.isfile(os.path.join(output_dir, file)):
|
||||
# Split the file name and extension
|
||||
file_name, ext = os.path.splitext(file)
|
||||
|
||||
# Copy the v2-inference-v.yaml file to the current file, with a .yaml extension
|
||||
if v2 and v_parameterization:
|
||||
print(f'Saving v2-inference-v.yaml as {output_dir}/{file_name}.yaml')
|
||||
shutil.copy(
|
||||
f'./v2_inference/v2-inference-v.yaml',
|
||||
f'{output_dir}/{file_name}.yaml',
|
||||
)
|
||||
elif v2:
|
||||
print(f'Saving v2-inference.yaml as {output_dir}/{file_name}.yaml')
|
||||
shutil.copy(
|
||||
f'./v2_inference/v2-inference.yaml',
|
||||
f'{output_dir}/{file_name}.yaml',
|
||||
)
|
||||
|
||||
def set_pretrained_model_name_or_path_input(value, v2, v_parameterization):
|
||||
# define a list of substrings to search for
|
||||
substrings_v2 = [
|
||||
'stabilityai/stable-diffusion-2-1-base',
|
||||
'stabilityai/stable-diffusion-2-base',
|
||||
]
|
||||
|
||||
# check if $v2 and $v_parameterization are empty and if $pretrained_model_name_or_path contains any of the substrings in the v2 list
|
||||
if str(value) in substrings_v2:
|
||||
print('SD v2 model detected. Setting --v2 parameter')
|
||||
v2 = True
|
||||
v_parameterization = False
|
||||
|
||||
return value, v2, v_parameterization
|
||||
|
||||
# define a list of substrings to search for v-objective
|
||||
substrings_v_parameterization = [
|
||||
'stabilityai/stable-diffusion-2-1',
|
||||
'stabilityai/stable-diffusion-2',
|
||||
]
|
||||
|
||||
# check if $v2 and $v_parameterization are empty and if $pretrained_model_name_or_path contains any of the substrings in the v_parameterization list
|
||||
if str(value) in substrings_v_parameterization:
|
||||
print(
|
||||
'SD v2 v_parameterization detected. Setting --v2 parameter and --v_parameterization'
|
||||
)
|
||||
v2 = True
|
||||
v_parameterization = True
|
||||
|
||||
return value, v2, v_parameterization
|
||||
|
||||
# define a list of substrings to v1.x
|
||||
substrings_v1_model = [
|
||||
'CompVis/stable-diffusion-v1-4',
|
||||
'runwayml/stable-diffusion-v1-5',
|
||||
]
|
||||
|
||||
if str(value) in substrings_v1_model:
|
||||
v2 = False
|
||||
v_parameterization = False
|
||||
|
||||
return value, v2, v_parameterization
|
||||
|
||||
if value == 'custom':
|
||||
value = ''
|
||||
v2 = False
|
||||
v_parameterization = False
|
||||
|
||||
return value, v2, v_parameterization
|
||||
@ -1133,14 +1133,6 @@ def load_vae(vae_id, dtype):
|
||||
return vae
|
||||
|
||||
|
||||
def get_epoch_ckpt_name(use_safetensors, epoch):
|
||||
return f"epoch-{epoch:06d}" + (".safetensors" if use_safetensors else ".ckpt")
|
||||
|
||||
|
||||
def get_last_ckpt_name(use_safetensors):
|
||||
return f"last" + (".safetensors" if use_safetensors else ".ckpt")
|
||||
|
||||
|
||||
# endregion
|
||||
|
||||
|
||||
@ -1187,4 +1179,4 @@ if __name__ == '__main__':
|
||||
for ar in aspect_ratios:
|
||||
if ar in ars:
|
||||
print("error! duplicate ar:", ar)
|
||||
ars.add(ar)
|
||||
ars.add(ar)
|
||||
|
||||
1373
library/train_util.py
Normal file
1373
library/train_util.py
Normal file
File diff suppressed because it is too large
Load Diff
302
lora_gui.py
302
lora_gui.py
@ -18,6 +18,8 @@ from library.common_gui import (
|
||||
get_any_file_path,
|
||||
get_saveasfile_path,
|
||||
color_aug_changed,
|
||||
save_inference_file,
|
||||
set_pretrained_model_name_or_path_input,
|
||||
)
|
||||
from library.dreambooth_folder_creation_gui import (
|
||||
gradio_dreambooth_folder_creation_tab,
|
||||
@ -74,7 +76,13 @@ def save_configuration(
|
||||
color_aug,
|
||||
flip_aug,
|
||||
clip_skip,
|
||||
gradient_accumulation_steps,
|
||||
mem_eff_attn,
|
||||
output_name,
|
||||
):
|
||||
# Get list of function parameters and values
|
||||
parameters = list(locals().items())
|
||||
|
||||
original_file_path = file_path
|
||||
|
||||
save_as_bool = True if save_as.get('label') == 'True' else False
|
||||
@ -94,82 +102,51 @@ def save_configuration(
|
||||
|
||||
# Return the values of the variables as a dictionary
|
||||
variables = {
|
||||
'pretrained_model_name_or_path': pretrained_model_name_or_path,
|
||||
'v2': v2,
|
||||
'v_parameterization': v_parameterization,
|
||||
'logging_dir': logging_dir,
|
||||
'train_data_dir': train_data_dir,
|
||||
'reg_data_dir': reg_data_dir,
|
||||
'output_dir': output_dir,
|
||||
'max_resolution': max_resolution,
|
||||
'lr_scheduler': lr_scheduler,
|
||||
'lr_warmup': lr_warmup,
|
||||
'train_batch_size': train_batch_size,
|
||||
'epoch': epoch,
|
||||
'save_every_n_epochs': save_every_n_epochs,
|
||||
'mixed_precision': mixed_precision,
|
||||
'save_precision': save_precision,
|
||||
'seed': seed,
|
||||
'num_cpu_threads_per_process': num_cpu_threads_per_process,
|
||||
'cache_latent': cache_latent,
|
||||
'caption_extention': caption_extention,
|
||||
'enable_bucket': enable_bucket,
|
||||
'gradient_checkpointing': gradient_checkpointing,
|
||||
'full_fp16': full_fp16,
|
||||
'no_token_padding': no_token_padding,
|
||||
'stop_text_encoder_training': stop_text_encoder_training,
|
||||
'use_8bit_adam': use_8bit_adam,
|
||||
'xformers': xformers,
|
||||
'save_model_as': save_model_as,
|
||||
'shuffle_caption': shuffle_caption,
|
||||
'save_state': save_state,
|
||||
'resume': resume,
|
||||
'prior_loss_weight': prior_loss_weight,
|
||||
'text_encoder_lr': text_encoder_lr,
|
||||
'unet_lr': unet_lr,
|
||||
'network_dim': network_dim,
|
||||
'lora_network_weights': lora_network_weights,
|
||||
'color_aug': color_aug,
|
||||
'flip_aug': flip_aug,
|
||||
'clip_skip': clip_skip,
|
||||
name: value
|
||||
for name, value in parameters # locals().items()
|
||||
if name
|
||||
not in [
|
||||
'file_path',
|
||||
'save_as',
|
||||
]
|
||||
}
|
||||
|
||||
# Save the data to the selected file
|
||||
with open(file_path, 'w') as file:
|
||||
json.dump(variables, file)
|
||||
json.dump(variables, file, indent=2)
|
||||
|
||||
return file_path
|
||||
|
||||
|
||||
def open_configuration(
|
||||
file_path,
|
||||
pretrained_model_name_or_path,
|
||||
v2,
|
||||
v_parameterization,
|
||||
logging_dir,
|
||||
train_data_dir,
|
||||
reg_data_dir,
|
||||
output_dir,
|
||||
max_resolution,
|
||||
lr_scheduler,
|
||||
lr_warmup,
|
||||
train_batch_size,
|
||||
epoch,
|
||||
save_every_n_epochs,
|
||||
mixed_precision,
|
||||
save_precision,
|
||||
seed,
|
||||
num_cpu_threads_per_process,
|
||||
cache_latent,
|
||||
caption_extention,
|
||||
enable_bucket,
|
||||
pretrained_model_name_or_path_input,
|
||||
v2_input,
|
||||
v_parameterization_input,
|
||||
logging_dir_input,
|
||||
train_data_dir_input,
|
||||
reg_data_dir_input,
|
||||
output_dir_input,
|
||||
max_resolution_input,
|
||||
lr_scheduler_input,
|
||||
lr_warmup_input,
|
||||
train_batch_size_input,
|
||||
epoch_input,
|
||||
save_every_n_epochs_input,
|
||||
mixed_precision_input,
|
||||
save_precision_input,
|
||||
seed_input,
|
||||
num_cpu_threads_per_process_input,
|
||||
cache_latent_input,
|
||||
caption_extention_input,
|
||||
enable_bucket_input,
|
||||
gradient_checkpointing,
|
||||
full_fp16,
|
||||
no_token_padding,
|
||||
stop_text_encoder_training,
|
||||
use_8bit_adam,
|
||||
xformers,
|
||||
save_model_as,
|
||||
full_fp16_input,
|
||||
no_token_padding_input,
|
||||
stop_text_encoder_training_input,
|
||||
use_8bit_adam_input,
|
||||
xformers_input,
|
||||
save_model_as_dropdown,
|
||||
shuffle_caption,
|
||||
save_state,
|
||||
resume,
|
||||
@ -181,66 +158,31 @@ def open_configuration(
|
||||
color_aug,
|
||||
flip_aug,
|
||||
clip_skip,
|
||||
gradient_accumulation_steps,
|
||||
mem_eff_attn,
|
||||
output_name,
|
||||
):
|
||||
# Get list of function parameters and values
|
||||
parameters = list(locals().items())
|
||||
|
||||
original_file_path = file_path
|
||||
file_path = get_file_path(file_path)
|
||||
# print(file_path)
|
||||
|
||||
if not file_path == '' and not file_path == None:
|
||||
# load variables from JSON file
|
||||
with open(file_path, 'r') as f:
|
||||
my_data = json.load(f)
|
||||
my_data_lora = json.load(f)
|
||||
print("Loading config...")
|
||||
else:
|
||||
file_path = original_file_path # In case a file_path was provided and the user decide to cancel the open action
|
||||
my_data = {}
|
||||
|
||||
# Return the values of the variables as a dictionary
|
||||
return (
|
||||
file_path,
|
||||
my_data.get(
|
||||
'pretrained_model_name_or_path', pretrained_model_name_or_path
|
||||
),
|
||||
my_data.get('v2', v2),
|
||||
my_data.get('v_parameterization', v_parameterization),
|
||||
my_data.get('logging_dir', logging_dir),
|
||||
my_data.get('train_data_dir', train_data_dir),
|
||||
my_data.get('reg_data_dir', reg_data_dir),
|
||||
my_data.get('output_dir', output_dir),
|
||||
my_data.get('max_resolution', max_resolution),
|
||||
my_data.get('lr_scheduler', lr_scheduler),
|
||||
my_data.get('lr_warmup', lr_warmup),
|
||||
my_data.get('train_batch_size', train_batch_size),
|
||||
my_data.get('epoch', epoch),
|
||||
my_data.get('save_every_n_epochs', save_every_n_epochs),
|
||||
my_data.get('mixed_precision', mixed_precision),
|
||||
my_data.get('save_precision', save_precision),
|
||||
my_data.get('seed', seed),
|
||||
my_data.get(
|
||||
'num_cpu_threads_per_process', num_cpu_threads_per_process
|
||||
),
|
||||
my_data.get('cache_latent', cache_latent),
|
||||
my_data.get('caption_extention', caption_extention),
|
||||
my_data.get('enable_bucket', enable_bucket),
|
||||
my_data.get('gradient_checkpointing', gradient_checkpointing),
|
||||
my_data.get('full_fp16', full_fp16),
|
||||
my_data.get('no_token_padding', no_token_padding),
|
||||
my_data.get('stop_text_encoder_training', stop_text_encoder_training),
|
||||
my_data.get('use_8bit_adam', use_8bit_adam),
|
||||
my_data.get('xformers', xformers),
|
||||
my_data.get('save_model_as', save_model_as),
|
||||
my_data.get('shuffle_caption', shuffle_caption),
|
||||
my_data.get('save_state', save_state),
|
||||
my_data.get('resume', resume),
|
||||
my_data.get('prior_loss_weight', prior_loss_weight),
|
||||
my_data.get('text_encoder_lr', text_encoder_lr),
|
||||
my_data.get('unet_lr', unet_lr),
|
||||
my_data.get('network_dim', network_dim),
|
||||
my_data.get('lora_network_weights', lora_network_weights),
|
||||
my_data.get('color_aug', color_aug),
|
||||
my_data.get('flip_aug', flip_aug),
|
||||
my_data.get('clip_skip', clip_skip),
|
||||
)
|
||||
my_data_lora = {}
|
||||
|
||||
values = [file_path]
|
||||
for key, value in parameters:
|
||||
# Set the value in the dictionary to the corresponding value in `my_data`, or the default value if not found
|
||||
if not key in ['file_path']:
|
||||
values.append(my_data_lora.get(key, value))
|
||||
return tuple(values)
|
||||
|
||||
|
||||
def train_model(
|
||||
@ -282,22 +224,10 @@ def train_model(
|
||||
color_aug,
|
||||
flip_aug,
|
||||
clip_skip,
|
||||
gradient_accumulation_steps,
|
||||
mem_eff_attn,
|
||||
output_name,
|
||||
):
|
||||
def save_inference_file(output_dir, v2, v_parameterization):
|
||||
# Copy inference model for v2 if required
|
||||
if v2 and v_parameterization:
|
||||
print(f'Saving v2-inference-v.yaml as {output_dir}/last.yaml')
|
||||
shutil.copy(
|
||||
f'./v2_inference/v2-inference-v.yaml',
|
||||
f'{output_dir}/last.yaml',
|
||||
)
|
||||
elif v2:
|
||||
print(f'Saving v2-inference.yaml as {output_dir}/last.yaml')
|
||||
shutil.copy(
|
||||
f'./v2_inference/v2-inference.yaml',
|
||||
f'{output_dir}/last.yaml',
|
||||
)
|
||||
|
||||
if pretrained_model_name_or_path == '':
|
||||
msgbox('Source model information is missing')
|
||||
return
|
||||
@ -364,17 +294,6 @@ def train_model(
|
||||
# Print the result
|
||||
print(f'Folder {folder}: {steps} steps')
|
||||
|
||||
# Print the result
|
||||
# print(f"{total_steps} total steps")
|
||||
|
||||
# if reg_data_dir == '':
|
||||
# reg_factor = 1
|
||||
# else:
|
||||
# print(
|
||||
# 'Regularisation images are used... Will double the number of steps required...'
|
||||
# )
|
||||
# reg_factor = 2
|
||||
|
||||
# calculate max_train_steps
|
||||
max_train_steps = int(
|
||||
math.ceil(
|
||||
@ -425,6 +344,8 @@ def train_model(
|
||||
run_cmd += ' --color_aug'
|
||||
if flip_aug:
|
||||
run_cmd += ' --flip_aug'
|
||||
if mem_eff_attn:
|
||||
run_cmd += ' --mem_eff_attn'
|
||||
run_cmd += (
|
||||
f' --pretrained_model_name_or_path="{pretrained_model_name_or_path}"'
|
||||
)
|
||||
@ -475,68 +396,23 @@ def train_model(
|
||||
run_cmd += f' --network_weights="{lora_network_weights}"'
|
||||
if int(clip_skip) > 1:
|
||||
run_cmd += f' --clip_skip={str(clip_skip)}'
|
||||
if int(gradient_accumulation_steps) > 1:
|
||||
run_cmd += f' --gradient_accumulation_steps={int(gradient_accumulation_steps)}'
|
||||
# if not vae == '':
|
||||
# run_cmd += f' --vae="{vae}"'
|
||||
if not output_name == '':
|
||||
run_cmd += f' --output_name="{output_name}"'
|
||||
|
||||
print(run_cmd)
|
||||
# Run the command
|
||||
subprocess.run(run_cmd)
|
||||
|
||||
# check if output_dir/last is a folder... therefore it is a diffuser model
|
||||
last_dir = pathlib.Path(f'{output_dir}/last')
|
||||
last_dir = pathlib.Path(f'{output_dir}/{output_name}')
|
||||
|
||||
if not last_dir.is_dir():
|
||||
# Copy inference model for v2 if required
|
||||
save_inference_file(output_dir, v2, v_parameterization)
|
||||
|
||||
|
||||
def set_pretrained_model_name_or_path_input(value, v2, v_parameterization):
|
||||
# define a list of substrings to search for
|
||||
substrings_v2 = [
|
||||
'stabilityai/stable-diffusion-2-1-base',
|
||||
'stabilityai/stable-diffusion-2-base',
|
||||
]
|
||||
|
||||
# check if $v2 and $v_parameterization are empty and if $pretrained_model_name_or_path contains any of the substrings in the v2 list
|
||||
if str(value) in substrings_v2:
|
||||
print('SD v2 model detected. Setting --v2 parameter')
|
||||
v2 = True
|
||||
v_parameterization = False
|
||||
|
||||
return value, v2, v_parameterization
|
||||
|
||||
# define a list of substrings to search for v-objective
|
||||
substrings_v_parameterization = [
|
||||
'stabilityai/stable-diffusion-2-1',
|
||||
'stabilityai/stable-diffusion-2',
|
||||
]
|
||||
|
||||
# check if $v2 and $v_parameterization are empty and if $pretrained_model_name_or_path contains any of the substrings in the v_parameterization list
|
||||
if str(value) in substrings_v_parameterization:
|
||||
print(
|
||||
'SD v2 v_parameterization detected. Setting --v2 parameter and --v_parameterization'
|
||||
)
|
||||
v2 = True
|
||||
v_parameterization = True
|
||||
|
||||
return value, v2, v_parameterization
|
||||
|
||||
# define a list of substrings to v1.x
|
||||
substrings_v1_model = [
|
||||
'CompVis/stable-diffusion-v1-4',
|
||||
'runwayml/stable-diffusion-v1-5',
|
||||
]
|
||||
|
||||
if str(value) in substrings_v1_model:
|
||||
v2 = False
|
||||
v_parameterization = False
|
||||
|
||||
return value, v2, v_parameterization
|
||||
|
||||
if value == 'custom':
|
||||
value = ''
|
||||
v2 = False
|
||||
v_parameterization = False
|
||||
|
||||
return value, v2, v_parameterization
|
||||
save_inference_file(output_dir, v2, v_parameterization, output_name)
|
||||
|
||||
|
||||
def UI(username, password):
|
||||
@ -710,6 +586,13 @@ def lora_tab(
|
||||
logging_dir_input_folder.click(
|
||||
get_folder_path, outputs=logging_dir_input
|
||||
)
|
||||
with gr.Row():
|
||||
output_name = gr.Textbox(
|
||||
label='Model output name',
|
||||
placeholder='Name of the model to output',
|
||||
value='last',
|
||||
interactive=True,
|
||||
)
|
||||
train_data_dir_input.change(
|
||||
remove_doublequote,
|
||||
inputs=[train_data_dir_input],
|
||||
@ -745,7 +628,6 @@ def lora_tab(
|
||||
outputs=lora_network_weights,
|
||||
)
|
||||
with gr.Row():
|
||||
# learning_rate_input = gr.Textbox(label='Learning rate', value=1e-4, visible=False)
|
||||
lr_scheduler_input = gr.Dropdown(
|
||||
label='LR Scheduler',
|
||||
choices=[
|
||||
@ -851,16 +733,19 @@ def lora_tab(
|
||||
label='No token padding', value=False
|
||||
)
|
||||
|
||||
gradient_checkpointing_input = gr.Checkbox(
|
||||
gradient_checkpointing = gr.Checkbox(
|
||||
label='Gradient checkpointing', value=False
|
||||
)
|
||||
gradient_accumulation_steps = gr.Number(
|
||||
label='Gradient accumulate steps', value='1'
|
||||
)
|
||||
|
||||
shuffle_caption = gr.Checkbox(
|
||||
label='Shuffle caption', value=False
|
||||
)
|
||||
with gr.Row():
|
||||
save_state = gr.Checkbox(
|
||||
label='Save training state', value=False
|
||||
prior_loss_weight = gr.Number(
|
||||
label='Prior loss weight', value=1.0
|
||||
)
|
||||
color_aug = gr.Checkbox(
|
||||
label='Color augmentation', value=False
|
||||
@ -874,16 +759,25 @@ def lora_tab(
|
||||
clip_skip = gr.Slider(
|
||||
label='Clip skip', value='1', minimum=1, maximum=12, step=1
|
||||
)
|
||||
mem_eff_attn = gr.Checkbox(
|
||||
label='Memory efficient attention', value=False
|
||||
)
|
||||
with gr.Row():
|
||||
save_state = gr.Checkbox(
|
||||
label='Save training state', value=False
|
||||
)
|
||||
resume = gr.Textbox(
|
||||
label='Resume from saved training state',
|
||||
placeholder='path to "last-state" state folder to resume from',
|
||||
)
|
||||
resume_button = gr.Button('📂', elem_id='open_folder_small')
|
||||
resume_button.click(get_folder_path, outputs=resume)
|
||||
prior_loss_weight = gr.Number(
|
||||
label='Prior loss weight', value=1.0
|
||||
)
|
||||
# vae = gr.Textbox(
|
||||
# label='VAE',
|
||||
# placeholder='(Optiona) path to checkpoint of vae to replace for training',
|
||||
# )
|
||||
# vae_button = gr.Button('📂', elem_id='open_folder_small')
|
||||
# vae_button.click(get_any_file_path, outputs=vae)
|
||||
with gr.Tab('Tools'):
|
||||
gr.Markdown(
|
||||
'This section provide Dreambooth tools to help setup your dataset...'
|
||||
@ -908,7 +802,6 @@ def lora_tab(
|
||||
reg_data_dir_input,
|
||||
output_dir_input,
|
||||
max_resolution_input,
|
||||
# learning_rate_input,
|
||||
lr_scheduler_input,
|
||||
lr_warmup_input,
|
||||
train_batch_size_input,
|
||||
@ -921,7 +814,7 @@ def lora_tab(
|
||||
cache_latent_input,
|
||||
caption_extention_input,
|
||||
enable_bucket_input,
|
||||
gradient_checkpointing_input,
|
||||
gradient_checkpointing,
|
||||
full_fp16_input,
|
||||
no_token_padding_input,
|
||||
stop_text_encoder_training_input,
|
||||
@ -939,6 +832,9 @@ def lora_tab(
|
||||
color_aug,
|
||||
flip_aug,
|
||||
clip_skip,
|
||||
gradient_accumulation_steps,
|
||||
mem_eff_attn,
|
||||
output_name,
|
||||
]
|
||||
|
||||
button_open_config.click(
|
||||
|
||||
@ -155,4 +155,4 @@ if __name__ == '__main__':
|
||||
parser.add_argument("--device", type=str, default=None, help="device to use, 'cuda' for GPU / 計算を行うデバイス、'cuda'でGPUを使う")
|
||||
|
||||
args = parser.parse_args()
|
||||
svd(args)
|
||||
svd(args)
|
||||
|
||||
1099
train_db.py
1099
train_db.py
File diff suppressed because it is too large
Load Diff
296
train_db_README-ja.md
Normal file
296
train_db_README-ja.md
Normal file
@ -0,0 +1,296 @@
|
||||
DreamBoothのガイドです。LoRA等の追加ネットワークの学習にも同じ手順を使います。
|
||||
|
||||
# 概要
|
||||
|
||||
スクリプトの主な機能は以下の通りです。
|
||||
|
||||
- 8bit Adam optimizerおよびlatentのキャッシュによる省メモリ化(ShivamShrirao氏版と同様)。
|
||||
- xformersによる省メモリ化。
|
||||
- 512x512だけではなく任意サイズでの学習。
|
||||
- augmentationによる品質の向上。
|
||||
- DreamBoothだけではなくText Encoder+U-Netのfine tuningに対応。
|
||||
- StableDiffusion形式でのモデルの読み書き。
|
||||
- Aspect Ratio Bucketing。
|
||||
- Stable Diffusion v2.0対応。
|
||||
|
||||
# 学習の手順
|
||||
|
||||
## step 1. 環境整備
|
||||
|
||||
このリポジトリのREADMEを参照してください。
|
||||
|
||||
|
||||
## step 2. identifierとclassを決める
|
||||
|
||||
学ばせたい対象を結びつける単語identifierと、対象の属するclassを決めます。
|
||||
|
||||
(instanceなどいろいろな呼び方がありますが、とりあえず元の論文に合わせます。)
|
||||
|
||||
以下ごく簡単に説明します(詳しくは調べてください)。
|
||||
|
||||
classは学習対象の一般的な種別です。たとえば特定の犬種を学ばせる場合には、classはdogになります。アニメキャラならモデルによりboyやgirl、1boyや1girlになるでしょう。
|
||||
|
||||
identifierは学習対象を識別して学習するためのものです。任意の単語で構いませんが、元論文によると「tokinizerで1トークンになる3文字以下でレアな単語」が良いとのことです。
|
||||
|
||||
identifierとclassを使い、たとえば「shs dog」などでモデルを学習することで、学習させたい対象をclassから識別して学習できます。
|
||||
|
||||
画像生成時には「shs dog」とすれば学ばせた犬種の画像が生成されます。
|
||||
|
||||
(identifierとして私が最近使っているものを参考までに挙げると、``shs sts scs cpc coc cic msm usu ici lvl cic dii muk ori hru rik koo yos wny`` などです。)
|
||||
|
||||
## step 3. 学習用画像の準備
|
||||
学習用画像を格納するフォルダを作成します。 __さらにその中に__ 、以下の名前でディレクトリを作成します。
|
||||
|
||||
```
|
||||
<繰り返し回数>_<identifier> <class>
|
||||
```
|
||||
|
||||
間の``_``を忘れないでください。
|
||||
|
||||
繰り返し回数は、正則化画像と枚数を合わせるために指定します(後述します)。
|
||||
|
||||
たとえば「sls frog」というプロンプトで、データを20回繰り返す場合、「20_sls frog」となります。以下のようになります。
|
||||
|
||||

|
||||
|
||||
## step 4. 正則化画像の準備
|
||||
正則化画像を使う場合の手順です。使わずに学習することもできます(正則化画像を使わないと区別ができなくなるので対象class全体が影響を受けます)。
|
||||
|
||||
正則化画像を格納するフォルダを作成します。 __さらにその中に__ ``<繰り返し回数>_<class>`` という名前でディレクトリを作成します。
|
||||
|
||||
たとえば「frog」というプロンプトで、データを繰り返さない(1回だけ)場合、以下のようになります。
|
||||
|
||||
|
||||
|
||||
繰り返し回数は「 __学習用画像の繰り返し回数×学習用画像の枚数≧正則化画像の繰り返し回数×正則化画像の枚数__ 」となるように指定してください。
|
||||
|
||||
(1 epochのデータ数が「学習用画像の繰り返し回数×学習用画像の枚数」となります。正則化画像の枚数がそれより多いと、余った部分の正則化画像は使用されません。)
|
||||
|
||||
## step 5. 学習の実行
|
||||
スクリプトを実行します。最大限、メモリを節約したコマンドは以下のようになります(実際には1行で入力します)。
|
||||
|
||||
※LoRA等の追加ネットワークを学習する場合のコマンドは ``train_db.py`` ではなく ``train_network.py`` となります。また追加でnetwork_\*オプションが必要となりますので、LoRAのガイドを参照してください。
|
||||
|
||||
```
|
||||
accelerate launch --num_cpu_threads_per_process 8 train_db.py
|
||||
--pretrained_model_name_or_path=<.ckptまたは.safetensordまたはDiffusers版モデルのディレクトリ>
|
||||
--train_data_dir=<学習用データのディレクトリ>
|
||||
--reg_data_dir=<正則化画像のディレクトリ>
|
||||
--output_dir=<学習したモデルの出力先ディレクトリ>
|
||||
--prior_loss_weight=1.0
|
||||
--resolution=512
|
||||
--train_batch_size=1
|
||||
--learning_rate=1e-6
|
||||
--max_train_steps=1600
|
||||
--use_8bit_adam
|
||||
--xformers
|
||||
--mixed_precision="bf16"
|
||||
--cache_latents
|
||||
--gradient_checkpointing
|
||||
```
|
||||
|
||||
num_cpu_threads_per_processにはCPUコア数を指定するとよいようです。
|
||||
|
||||
pretrained_model_name_or_pathに追加学習を行う元となるモデルを指定します。Stable Diffusionのcheckpointファイル(.ckptまたは.safetensors)、Diffusersのローカルディスクにあるモデルディレクトリ、DiffusersのモデルID("stabilityai/stable-diffusion-2"など)が指定できます。学習後のモデルの保存形式はデフォルトでは元のモデルと同じになります(save_model_asオプションで変更できます)。
|
||||
|
||||
prior_loss_weightは正則化画像のlossの重みです。通常は1.0を指定します。
|
||||
|
||||
resolutionは画像のサイズ(解像度、幅と高さ)になります。bucketing(後述)を用いない場合、学習用画像、正則化画像はこのサイズとしてください。
|
||||
|
||||
train_batch_sizeは学習時のバッチサイズです。max_train_stepsを1600とします。学習率learning_rateは、diffusers版では5e-6ですがStableDiffusion版は1e-6ですのでここでは1e-6を指定しています。
|
||||
|
||||
省メモリ化のためmixed_precision="bf16"(または"fp16")、およびgradient_checkpointing を指定します。
|
||||
|
||||
xformersオプションを指定し、xformersのCrossAttentionを用います。xformersをインストールしていない場合、エラーとなる場合(mixed_precisionなしの場合、私の環境ではエラーとなりました)、代わりにmem_eff_attnオプションを指定すると省メモリ版CrossAttentionを使用します(速度は遅くなります)。
|
||||
|
||||
省メモリ化のためcache_latentsオプションを指定してVAEの出力をキャッシュします。
|
||||
|
||||
ある程度メモリがある場合はたとえば以下のように指定します。
|
||||
|
||||
```
|
||||
accelerate launch --num_cpu_threads_per_process 8 train_db.py
|
||||
--pretrained_model_name_or_path=<.ckptまたは.safetensordまたはDiffusers版モデルのディレクトリ>
|
||||
--train_data_dir=<学習用データのディレクトリ>
|
||||
--reg_data_dir=<正則化画像のディレクトリ>
|
||||
--output_dir=<学習したモデルの出力先ディレクトリ>
|
||||
--prior_loss_weight=1.0
|
||||
--resolution=512
|
||||
--train_batch_size=4
|
||||
--learning_rate=1e-6
|
||||
--max_train_steps=400
|
||||
--use_8bit_adam
|
||||
--xformers
|
||||
--mixed_precision="bf16"
|
||||
--cache_latents
|
||||
```
|
||||
|
||||
gradient_checkpointingを外し高速化します(メモリ使用量は増えます)。バッチサイズを増やし、高速化と精度向上を図ります。
|
||||
|
||||
bucketing(後述)を利用しかつaugmentation(後述)を使う場合の例は以下のようになります。
|
||||
|
||||
```
|
||||
accelerate launch --num_cpu_threads_per_process 8 train_db.py
|
||||
--pretrained_model_name_or_path=<.ckptまたは.safetensordまたはDiffusers版モデルのディレクトリ>
|
||||
--train_data_dir=<学習用データのディレクトリ>
|
||||
--reg_data_dir=<正則化画像のディレクトリ>
|
||||
--output_dir=<学習したモデルの出力先ディレクトリ>
|
||||
--resolution=768,512
|
||||
--train_batch_size=20 --learning_rate=5e-6 --max_train_steps=800
|
||||
--use_8bit_adam --xformers --mixed_precision="bf16"
|
||||
--save_every_n_epochs=1 --save_state --save_precision="bf16"
|
||||
--logging_dir=logs
|
||||
--enable_bucket --min_bucket_reso=384 --max_bucket_reso=1280
|
||||
--color_aug --flip_aug --gradient_checkpointing --seed 42
|
||||
```
|
||||
|
||||
### ステップ数について
|
||||
省メモリ化のため、ステップ当たりの学習回数がtrain_dreambooth.pyの半分になっています(対象の画像と正則化画像を同一のバッチではなく別のバッチに分割して学習するため)。
|
||||
元のDiffusers版やXavierXiao氏のStableDiffusion版とほぼ同じ学習を行うには、ステップ数を倍にしてください。
|
||||
|
||||
(shuffle=Trueのため厳密にはデータの順番が変わってしまいますが、学習には大きな影響はないと思います。)
|
||||
|
||||
## 学習したモデルで画像生成する
|
||||
|
||||
学習が終わると指定したフォルダにlast.ckptという名前でcheckpointが出力されます(DiffUsers版モデルを学習した場合はlastフォルダになります)。
|
||||
|
||||
v1.4/1.5およびその他の派生モデルの場合、このモデルでAutomatic1111氏のWebUIなどで推論できます。models\Stable-diffusionフォルダに置いてください。
|
||||
|
||||
v2.xモデルでWebUIで画像生成する場合、モデルの仕様が記述された.yamlファイルが別途必要になります。v2.x baseの場合はv2-inference.yamlを、768/vの場合はv2-inference-v.yamlを、同じフォルダに置き、拡張子の前の部分をモデルと同じ名前にしてください。
|
||||
|
||||

|
||||
|
||||
各yamlファイルは[https://github.com/Stability-AI/stablediffusion/tree/main/configs/stable-diffusion](Stability AIのSD2.0のリポジトリ)にあります。
|
||||
|
||||
# その他の学習オプション
|
||||
|
||||
## Stable Diffusion 2.0対応 --v2 / --v_parameterization
|
||||
Hugging Faceのstable-diffusion-2-baseを使う場合はv2オプションを、stable-diffusion-2または768-v-ema.ckptを使う場合はv2とv_parameterizationの両方のオプションを指定してください。
|
||||
|
||||
なおSD 2.0の学習はText Encoderが大きくなっているためVRAM 12GBでは厳しいようです。
|
||||
|
||||
Stable Diffusion 2.0では大きく以下の点が変わっています。
|
||||
|
||||
1. 使用するTokenizer
|
||||
2. 使用するText Encoderおよび使用する出力層(2.0は最後から二番目の層を使う)
|
||||
3. Text Encoderの出力次元数(768->1024)
|
||||
4. U-Netの構造(CrossAttentionのhead数など)
|
||||
5. v-parameterization(サンプリング方法が変更されているらしい)
|
||||
|
||||
このうちbaseでは1~4が、baseのつかない方(768-v)では1~5が採用されています。1~4を有効にするのがv2オプション、5を有効にするのがv_parameterizationオプションです。
|
||||
|
||||
## 学習データの確認 --debug_dataset
|
||||
このオプションを付けることで学習を行う前に事前にどのような画像データ、キャプションで学習されるかを確認できます。Escキーを押すと終了してコマンドラインに戻ります。
|
||||
|
||||
※Colabなど画面が存在しない環境で実行するとハングするようですのでご注意ください。
|
||||
|
||||
## Text Encoderの学習を途中から行わない --stop_text_encoder_training
|
||||
stop_text_encoder_trainingオプションに数値を指定すると、そのステップ数以降はText Encoderの学習を行わずU-Netだけ学習します。場合によっては精度の向上が期待できるかもしれません。
|
||||
|
||||
(恐らくText Encoderだけ先に過学習することがあり、それを防げるのではないかと推測していますが、詳細な影響は不明です。)
|
||||
|
||||
## VAEを別途読み込んで学習する --vae
|
||||
vaeオプションにStable Diffusionのcheckpoint、VAEのcheckpointファイル、DiffusesのモデルまたはVAE(ともにローカルまたはHugging FaceのモデルIDが指定できます)のいずれかを指定すると、そのVAEを使って学習します(latentsのキャッシュ時または学習中のlatents取得時)。
|
||||
保存されるモデルはこのVAEを組み込んだものになります。
|
||||
|
||||
## 学習途中での保存 --save_every_n_epochs / --save_state / --resume
|
||||
save_every_n_epochsオプションに数値を指定すると、そのエポックごとに学習途中のモデルを保存します。
|
||||
|
||||
save_stateオプションを同時に指定すると、optimizer等の状態も含めた学習状態を合わせて保存します(checkpointから学習再開するのに比べて、精度の向上、学習時間の短縮が期待できます)。学習状態は保存先フォルダに"epoch-??????-state"(??????はエポック数)という名前のフォルダで出力されます。長時間にわたる学習時にご利用ください。
|
||||
|
||||
保存された学習状態から学習を再開するにはresumeオプションを使います。学習状態のフォルダを指定してください。
|
||||
|
||||
なおAcceleratorの仕様により(?)、エポック数、global stepは保存されておらず、resumeしたときにも1からになりますがご容赦ください。
|
||||
|
||||
## Tokenizerのパディングをしない --no_token_padding
|
||||
no_token_paddingオプションを指定するとTokenizerの出力をpaddingしません(Diffusers版の旧DreamBoothと同じ動きになります)。
|
||||
|
||||
## 任意サイズの画像での学習 --resolution
|
||||
正方形以外で学習できます。resolutionに「448,640」のように「幅,高さ」で指定してください。幅と高さは64で割り切れる必要があります。学習用画像、正則化画像のサイズを合わせてください。
|
||||
|
||||
個人的には縦長の画像を生成することが多いため「448,640」などで学習することもあります。
|
||||
|
||||
## Aspect Ratio Bucketing --enable_bucket / --min_bucket_reso / --max_bucket_reso
|
||||
enable_bucketオプションを指定すると有効になります。Stable Diffusionは512x512で学習されていますが、それに加えて256x768や384x640といった解像度でも学習します。
|
||||
|
||||
このオプションを指定した場合は、学習用画像、正則化画像を特定の解像度に統一する必要はありません。いくつかの解像度(アスペクト比)から最適なものを選び、その解像度で学習します。
|
||||
解像度は64ピクセル単位のため、元画像とアスペクト比が完全に一致しない場合がありますが、その場合は、はみ出した部分がわずかにトリミングされます。
|
||||
|
||||
解像度の最小サイズをmin_bucket_resoオプションで、最大サイズをmax_bucket_resoで指定できます。デフォルトはそれぞれ256、1024です。
|
||||
たとえば最小サイズに384を指定すると、256x1024や320x768などの解像度は使わなくなります。
|
||||
解像度を768x768のように大きくした場合、最大サイズに1280などを指定しても良いかもしれません。
|
||||
|
||||
なおAspect Ratio Bucketingを有効にするときには、正則化画像についても、学習用画像と似た傾向の様々な解像度を用意した方がいいかもしれません。
|
||||
|
||||
(ひとつのバッチ内の画像が学習用画像、正則化画像に偏らなくなるため。そこまで大きな影響はないと思いますが……。)
|
||||
|
||||
## augmentation --color_aug / --flip_aug
|
||||
augmentationは学習時に動的にデータを変化させることで、モデルの性能を上げる手法です。color_augで色合いを微妙に変えつつ、flip_augで左右反転をしつつ、学習します。
|
||||
|
||||
動的にデータを変化させるため、cache_latentsオプションと同時に指定できません。
|
||||
|
||||
## 保存時のデータ精度の指定 --save_precision
|
||||
save_precisionオプションにfloat、fp16、bf16のいずれかを指定すると、その形式でcheckpointを保存します(Stable Diffusion形式で保存する場合のみ)。checkpointのサイズを削減したい場合などにお使いください。
|
||||
|
||||
## 任意の形式で保存する --save_model_as
|
||||
モデルの保存形式を指定します。ckpt、safetensors、diffusers、diffusers_safetensorsのいずれかを指定してください。
|
||||
|
||||
Stable Diffusion形式(ckptまたはsafetensors)を読み込み、Diffusers形式で保存する場合、不足する情報はHugging Faceからv1.5またはv2.1の情報を落としてきて補完します。
|
||||
|
||||
## 学習ログの保存 --logging_dir / --log_prefix
|
||||
logging_dirオプションにログ保存先フォルダを指定してください。TensorBoard形式のログが保存されます。
|
||||
|
||||
たとえば--logging_dir=logsと指定すると、作業フォルダにlogsフォルダが作成され、その中の日時フォルダにログが保存されます。
|
||||
また--log_prefixオプションを指定すると、日時の前に指定した文字列が追加されます。「--logging_dir=logs --log_prefix=db_style1_」などとして識別用にお使いください。
|
||||
|
||||
TensorBoardでログを確認するには、別のコマンドプロンプトを開き、作業フォルダで以下のように入力します(tensorboardはDiffusersのインストール時にあわせてインストールされると思いますが、もし入っていないならpip install tensorboardで入れてください)。
|
||||
|
||||
```
|
||||
tensorboard --logdir=logs
|
||||
```
|
||||
|
||||
その後ブラウザを開き、http://localhost:6006/ へアクセスすると表示されます。
|
||||
|
||||
## 学習率のスケジューラ関連の指定 --lr_scheduler / --lr_warmup_steps
|
||||
lr_schedulerオプションで学習率のスケジューラをlinear, cosine, cosine_with_restarts, polynomial, constant, constant_with_warmupから選べます。デフォルトはconstantです。lr_warmup_stepsでスケジューラのウォームアップ(だんだん学習率を変えていく)ステップ数を指定できます。詳細については各自お調べください。
|
||||
|
||||
## 勾配をfp16とした学習(実験的機能) --full_fp16
|
||||
full_fp16オプションを指定すると勾配を通常のfloat32からfloat16(fp16)に変更して学習します(mixed precisionではなく完全なfp16学習になるようです)。
|
||||
これによりSD1.xの512x512サイズでは8GB未満、SD2.xの512x512サイズで12GB未満のVRAM使用量で学習できるようです。
|
||||
|
||||
あらかじめaccelerate configでfp16を指定し、オプションで ``mixed_precision="fp16"`` としてください(bf16では動作しません)。
|
||||
|
||||
メモリ使用量を最小化するためには、xformers、use_8bit_adam、cache_latents、gradient_checkpointingの各オプションを指定し、train_batch_sizeを1としてください。
|
||||
|
||||
(余裕があるようならtrain_batch_sizeを段階的に増やすと若干精度が上がるはずです。)
|
||||
|
||||
PyTorchのソースにパッチを当てて無理やり実現しています(PyTorch 1.12.1と1.13.0で確認)。精度はかなり落ちますし、途中で学習失敗する確率も高くなります。
|
||||
学習率やステップ数の設定もシビアなようです。それらを認識したうえで自己責任でお使いください。
|
||||
|
||||
# その他の学習方法
|
||||
|
||||
## 複数class、複数対象(identifier)の学習
|
||||
方法は単純で、学習用画像のフォルダ内に ``繰り返し回数_<identifier> <class>`` のフォルダを複数、正則化画像フォルダにも同様に ``繰り返し回数_<class>`` のフォルダを複数、用意してください。
|
||||
|
||||
たとえば「sls frog」と「cpc rabbit」を同時に学習する場合、以下のようになります。
|
||||
|
||||
|
||||
|
||||
classがひとつで対象が複数の場合、正則化画像フォルダはひとつで構いません。たとえば1girlにキャラAとキャラBがいる場合は次のようにします。
|
||||
|
||||
- train_girls
|
||||
- 10_sls 1girl
|
||||
- 10_cpc 1girl
|
||||
- reg_girls
|
||||
- 1_1girl
|
||||
|
||||
データ数にばらつきがある場合、繰り返し回数を調整してclass、identifierごとの枚数を統一すると良い結果が得られることがあるようです。
|
||||
|
||||
## DreamBoothでキャプションを使う
|
||||
学習用画像、正則化画像のフォルダに、画像と同じファイル名で、拡張子.caption(オプションで変えられます)のファイルを置くと、そのファイルからキャプションを読み込みプロンプトとして学習します。
|
||||
|
||||
※それらの画像の学習に、フォルダ名(identifier class)は使用されなくなります。
|
||||
|
||||
各画像にキャプションを付けることで(BLIP等を使っても良いでしょう)、学習したい属性をより明確にできるかもしれません。
|
||||
|
||||
キャプションファイルの拡張子はデフォルトで.captionです。--caption_extensionで変更できます。--shuffle_captionオプションで学習時のキャプションについて、カンマ区切りの各部分をシャッフルしながら学習します。
|
||||
|
||||
295
train_db_README.md
Normal file
295
train_db_README.md
Normal file
@ -0,0 +1,295 @@
|
||||
A guide to DreamBooth. The same procedure is used for training additional networks such as LoRA.
|
||||
|
||||
# overview
|
||||
|
||||
The main functions of the script are as follows.
|
||||
|
||||
- Memory saving by 8bit Adam optimizer and latent cache (similar to ShivamShirao's version).
|
||||
- Saved memory by xformers.
|
||||
- Study in any size, not just 512x512.
|
||||
- Quality improvement with augmentation.
|
||||
- Supports fine tuning of Text Encoder+U-Net as well as DreamBooth.
|
||||
- Read and write models in StableDiffusion format.
|
||||
- Aspect Ratio Bucketing.
|
||||
- Supports Stable Diffusion v2.0.
|
||||
|
||||
# learning procedure
|
||||
|
||||
## step 1. Environment improvement
|
||||
|
||||
See the README in this repository.
|
||||
|
||||
|
||||
## step 2. Determine identifier and class
|
||||
|
||||
Decide the word identifier that connects the target you want to learn and the class to which the target belongs.
|
||||
|
||||
(There are various names such as instance, but for the time being I will stick to the original paper.)
|
||||
|
||||
Here's a very brief explanation (look it up for more details).
|
||||
|
||||
class is the general type to learn. For example, if you want to learn a specific breed of dog, the class will be dog. Anime characters will be boy, girl, 1boy or 1girl depending on the model.
|
||||
|
||||
The identifier is for identifying and learning the learning target. Any word is fine, but according to the original paper, ``a rare word with 3 letters or less that becomes one token with tokinizer'' is good.
|
||||
|
||||
By using the identifier and class to train the model, for example, "shs dog", you can learn by identifying the object you want to learn from the class.
|
||||
|
||||
When generating an image, if you say "shs dog", an image of the learned dog breed will be generated.
|
||||
|
||||
(For reference, the identifier I use these days is ``shs sts scs cpc coc cic msm usu ici lvl cic dii muk ori hru rik koo yos wny``.)
|
||||
|
||||
## step 3. Prepare images for training
|
||||
Create a folder to store training images. __In addition, create a directory with the following name:
|
||||
|
||||
```
|
||||
<repeat count>_<identifier> <class>
|
||||
```
|
||||
|
||||
Don't forget the ``_`` between them.
|
||||
|
||||
The number of repetitions is specified to match the number of regularized images (described later).
|
||||
|
||||
For example, at the prompt "sls frog", to repeat the data 20 times, it would be "20_sls frog". It will be as follows.
|
||||
|
||||

|
||||
|
||||
## step 4. Preparing regularized images
|
||||
This is the procedure when using a regularized image. It is also possible to learn without using the regularization image (the whole target class is affected because it is impossible to distinguish without using the regularization image).
|
||||
|
||||
Create a folder to store the regularized images. __In addition, __ create a directory named ``<repeat count>_<class>``.
|
||||
|
||||
For example, with the prompt "frog" and without repeating the data (just once):
|
||||
|
||||

|
||||
|
||||
Specify the number of iterations so that " __ number of iterations of training images x number of training images ≥ number of iterations of regularization images x number of regularization images __".
|
||||
|
||||
(The number of data in one epoch is "number of repetitions of training images x number of training images". If the number of regularization images is more than that, the remaining regularization images will not be used.)
|
||||
|
||||
## step 5. Run training
|
||||
Run the script. The maximally memory-saving command looks like this (actually typed on one line):
|
||||
|
||||
*The command for learning additional networks such as LoRA is ``train_network.py`` instead of ``train_db.py``. You will also need additional network_\* options, so please refer to LoRA's guide.
|
||||
|
||||
```
|
||||
accelerate launch --num_cpu_threads_per_process 8 train_db.py
|
||||
--pretrained_model_name_or_path=<directory of .ckpt or .safetensord or Diffusers model>
|
||||
--train_data_dir=<training data directory>
|
||||
--reg_data_dir=<regularized image directory>
|
||||
--output_dir=<output destination directory for trained model>
|
||||
--prior_loss_weight=1.0
|
||||
--resolution=512
|
||||
--train_batch_size=1
|
||||
--learning_rate=1e-6
|
||||
--max_train_steps=1600
|
||||
--use_8bit_adam
|
||||
--xformers
|
||||
--mixed_precision="bf16"
|
||||
--cache_latents
|
||||
--gradient_checkpointing
|
||||
```
|
||||
|
||||
It seems to be good to specify the number of CPU cores for num_cpu_threads_per_process.
|
||||
|
||||
Specify the model to perform additional training in pretrained_model_name_or_path. You can specify a Stable Diffusion checkpoint file (.ckpt or .safetensors), a model directory on the Diffusers local disk, or a Diffusers model ID (such as "stabilityai/stable-diffusion-2"). The saved model after training will be saved in the same format as the original model by default (can be changed with the save_model_as option).
|
||||
|
||||
prior_loss_weight is the loss weight of the regularized image. Normally, specify 1.0.
|
||||
|
||||
resolution will be the size of the image (resolution, width and height). If bucketing (described later) is not used, use this size for training images and regularization images.
|
||||
|
||||
train_batch_size is the training batch size. Set max_train_steps to 1600. The learning rate learning_rate is 5e-6 in the diffusers version and 1e-6 in the StableDiffusion version, so 1e-6 is specified here.
|
||||
|
||||
Specify mixed_precision="bf16" (or "fp16") and gradient_checkpointing for memory saving.
|
||||
|
||||
Specify the xformers option and use xformers' CrossAttention. If you don't have xformers installed, if you get an error (without mixed_precision, it was an error in my environment), specify the mem_eff_attn option instead to use the memory-saving version of CrossAttention (speed will be slower) .
|
||||
|
||||
Cache VAE output with cache_latents option to save memory.
|
||||
|
||||
If you have a certain amount of memory, specify it as follows, for example.
|
||||
|
||||
```
|
||||
accelerate launch --num_cpu_threads_per_process 8 train_db.py
|
||||
--pretrained_model_name_or_path=<directory of .ckpt or .safetensord or Diffusers model>
|
||||
--train_data_dir=<training data directory>
|
||||
--reg_data_dir=<regularized image directory>
|
||||
--output_dir=<output destination directory for trained model>
|
||||
--prior_loss_weight=1.0
|
||||
--resolution=512
|
||||
--train_batch_size=4
|
||||
--learning_rate=1e-6
|
||||
--max_train_steps=400
|
||||
--use_8bit_adam
|
||||
--xformers
|
||||
--mixed_precision="bf16"
|
||||
--cache_latents
|
||||
```
|
||||
|
||||
Remove gradient_checkpointing to speed up (memory usage will increase). Increase the batch size to improve speed and accuracy.
|
||||
|
||||
An example of using bucketing (see below) and using augmentation (see below) looks like this:
|
||||
|
||||
```
|
||||
accelerate launch --num_cpu_threads_per_process 8 train_db.py
|
||||
--pretrained_model_name_or_path=<directory of .ckpt or .safetensord or Diffusers model>
|
||||
--train_data_dir=<training data directory>
|
||||
--reg_data_dir=<regularized image directory>
|
||||
--output_dir=<output destination directory for trained model>
|
||||
--resolution=768,512
|
||||
--train_batch_size=20 --learning_rate=5e-6 --max_train_steps=800
|
||||
--use_8bit_adam --xformers --mixed_precision="bf16"
|
||||
--save_every_n_epochs=1 --save_state --save_precision="bf16"
|
||||
--logging_dir=logs
|
||||
--enable_bucket --min_bucket_reso=384 --max_bucket_reso=1280
|
||||
--color_aug --flip_aug --gradient_checkpointing --seed 42
|
||||
```
|
||||
|
||||
### About the number of steps
|
||||
To save memory, the number of training steps per step is half that of train_drebooth.py (because the target image and the regularization image are divided into different batches instead of the same batch).
|
||||
Double the number of steps to get almost the same training as the original Diffusers version and XavierXiao's StableDiffusion version.
|
||||
|
||||
(Strictly speaking, the order of the data changes due to shuffle=True, but I don't think it has a big impact on learning.)
|
||||
|
||||
## Generate an image with the trained model
|
||||
|
||||
Name last.ckpt in the specified folder when learning is completed will output the checkpoint (if you learned the DiffUsers version model, it will be the last folder).
|
||||
|
||||
For v1.4/1.5 and other derived models, this model can be inferred by Automatic1111's WebUI, etc. Place it in the models\Stable-diffusion folder.
|
||||
|
||||
When generating images with WebUI with the v2.x model, a separate .yaml file that describes the model specifications is required. Place v2-inference.yaml for v2.x base and v2-inference-v.yaml for 768/v in the same folder and make the part before the extension the same name as the model.
|
||||
|
||||

|
||||
|
||||
Each yaml file can be found at [https://github.com/Stability-AI/stablediffusion/tree/main/configs/stable-diffusion] (Stability AI SD2.0 repository).
|
||||
|
||||
# Other study options
|
||||
|
||||
## Supports Stable Diffusion 2.0 --v2 / --v_parameterization
|
||||
Specify the v2 option when using Hugging Face's stable-diffusion-2-base, and specify both the v2 and v_parameterization options when using stable-diffusion-2 or 768-v-ema.ckpt.
|
||||
|
||||
In addition, learning SD 2.0 seems to be difficult with VRAM 12GB because the Text Encoder is getting bigger.
|
||||
|
||||
The following points have changed significantly in Stable Diffusion 2.0.
|
||||
|
||||
1. Tokenizer to use
|
||||
2. Which Text Encoder to use and which output layer to use (2.0 uses the penultimate layer)
|
||||
3. Output dimensionality of Text Encoder (768->1024)
|
||||
4. Structure of U-Net (number of heads of CrossAttention, etc.)
|
||||
5. v-parameterization (the sampling method seems to have changed)
|
||||
|
||||
Among these, 1 to 4 are adopted for base, and 1 to 5 are adopted for the one without base (768-v). Enabling 1-4 is the v2 option, and enabling 5 is the v_parameterization option.
|
||||
|
||||
## check training data --debug_dataset
|
||||
By adding this option, you can check what kind of image data and captions will be learned in advance before learning. Press Esc to exit and return to the command line.
|
||||
|
||||
*Please note that it seems to hang when executed in an environment where there is no screen such as Colab.
|
||||
|
||||
## Stop training Text Encoder --stop_text_encoder_training
|
||||
If you specify a numerical value for the stop_text_encoder_training option, after that number of steps, only the U-Net will be trained without training the Text Encoder. In some cases, the accuracy may be improved.
|
||||
|
||||
(Probably only the Text Encoder may overfit first, and I guess that it can be prevented, but the detailed impact is unknown.)
|
||||
|
||||
## Load and learn VAE separately --vae
|
||||
If you specify either a Stable Diffusion checkpoint, a VAE checkpoint file, a Diffuses model, or a VAE (both of which can specify a local or Hugging Face model ID) in the vae option, that VAE is used for learning (latents when caching or getting latents during learning).
|
||||
The saved model will incorporate this VAE.
|
||||
|
||||
## save during learning --save_every_n_epochs / --save_state / --resume
|
||||
Specifying a number for the save_every_n_epochs option saves the model during training every epoch.
|
||||
|
||||
If you specify the save_state option at the same time, the learning state including the state of the optimizer etc. will be saved together (compared to restarting learning from the checkpoint, you can expect to improve accuracy and shorten the learning time). The learning state is output in a folder named "epoch-??????-state" (?????? is the number of epochs) in the destination folder. Please use it when studying for a long time.
|
||||
|
||||
Use the resume option to resume training from a saved training state. Please specify the learning state folder.
|
||||
|
||||
Please note that due to the specifications of Accelerator (?), the number of epochs and global step are not saved, and it will start from 1 even when you resume.
|
||||
|
||||
## No tokenizer padding --no_token_padding
|
||||
The no_token_padding option does not pad the output of the Tokenizer (same behavior as Diffusers version of old DreamBooth).
|
||||
|
||||
## Training with arbitrary size images --resolution
|
||||
You can study outside the square. Please specify "width, height" like "448,640" in resolution. Width and height must be divisible by 64. Match the size of the training image and the regularization image.
|
||||
|
||||
Personally, I often generate vertically long images, so I sometimes learn with "448, 640".
|
||||
|
||||
## Aspect Ratio Bucketing --enable_bucket / --min_bucket_reso / --max_bucket_reso
|
||||
It is enabled by specifying the enable_bucket option. Stable Diffusion is trained at 512x512, but also at resolutions such as 256x768 and 384x640.
|
||||
|
||||
If you specify this option, you do not need to unify the training images and regularization images to a specific resolution. Choose from several resolutions (aspect ratios) and learn at that resolution.
|
||||
Since the resolution is 64 pixels, the aspect ratio may not be exactly the same as the original image.
|
||||
|
||||
You can specify the minimum size of the resolution with the min_bucket_reso option and the maximum size with the max_bucket_reso. The defaults are 256 and 1024 respectively.
|
||||
For example, specifying a minimum size of 384 will not use resolutions such as 256x1024 or 320x768.
|
||||
If you increase the resolution to 768x768, you may want to specify 1280 as the maximum size.
|
||||
|
||||
When Aspect Ratio Bucketing is enabled, it may be better to prepare regularization images with various resolutions that are similar to the training images.
|
||||
|
||||
(Because the images in one batch are not biased toward training images and regularization images.
|
||||
|
||||
## augmentation --color_aug / --flip_aug
|
||||
Augmentation is a method of improving model performance by dynamically changing data during learning. Learn while subtly changing the hue with color_aug and flipping left and right with flip_aug.
|
||||
|
||||
Since the data changes dynamically, it cannot be specified together with the cache_latents option.
|
||||
|
||||
## Specify data precision when saving --save_precision
|
||||
Specifying float, fp16, or bf16 as the save_precision option will save the checkpoint in that format (only when saving in Stable Diffusion format). Please use it when you want to reduce the size of checkpoint.
|
||||
|
||||
## save in any format --save_model_as
|
||||
Specify the save format of the model. Specify one of ckpt, safetensors, diffusers, diffusers_safetensors.
|
||||
|
||||
When reading Stable Diffusion format (ckpt or safetensors) and saving in Diffusers format, missing information is supplemented by dropping v1.5 or v2.1 information from Hugging Face.
|
||||
|
||||
## Save learning log --logging_dir / --log_prefix
|
||||
Specify the log save destination folder in the logging_dir option. Logs in TensorBoard format are saved.
|
||||
|
||||
For example, if you specify --logging_dir=logs, a logs folder will be created in your working folder, and logs will be saved in the date/time folder.
|
||||
Also, if you specify the --log_prefix option, the specified string will be added before the date and time. Use "--logging_dir=logs --log_prefix=db_style1_" for identification.
|
||||
|
||||
To check the log with TensorBoard, open another command prompt and enter the following in the working folder (I think tensorboard is installed when Diffusers is installed, but if it is not installed, pip install Please put it in tensorboard).
|
||||
|
||||
```
|
||||
tensorboard --logdir=logs
|
||||
```
|
||||
|
||||
Then open your browser and go to http://localhost:6006/ to see it.
|
||||
|
||||
## scheduler related specification of learning rate --lr_scheduler / --lr_warmup_steps
|
||||
You can choose the learning rate scheduler from linear, cosine, cosine_with_restarts, polynomial, constant, constant_with_warmup with the lr_scheduler option. Default is constant. With lr_warmup_steps, you can specify the number of steps to warm up the scheduler (gradually changing the learning rate). Please do your own research for details.
|
||||
|
||||
## Training with fp16 gradient (experimental feature) --full_fp16
|
||||
The full_fp16 option will change the gradient from normal float32 to float16 (fp16) and learn (it seems to be full fp16 learning instead of mixed precision).
|
||||
As a result, it seems that the SD1.x 512x512 size can be learned with a VRAM usage of less than 8GB, and the SD2.x 512x512 size can be learned with a VRAM usage of less than 12GB.
|
||||
|
||||
Specify fp16 in the accelerate config beforehand and optionally set ``mixed_precision="fp16"`` (bf16 does not work).
|
||||
|
||||
To minimize memory usage, use xformers, use_8bit_adam, cache_latents, gradient_checkpointing options and set train_batch_size to 1.
|
||||
|
||||
(If you can afford it, increasing the train_batch_size step by step should improve the accuracy a little.)
|
||||
|
||||
It is realized by patching the PyTorch source (confirmed with PyTorch 1.12.1 and 1.13.0). Accuracy will drop considerably, and the probability of learning failure on the way will also increase.
|
||||
The setting of the learning rate and the number of steps seems to be severe. Please be aware of them and use them at your own risk.
|
||||
|
||||
# Other learning methods
|
||||
|
||||
## Learning multiple classes, multiple identifiers
|
||||
The method is simple, multiple folders with ``Repetition count_<identifier> <class>`` in the training image folder, and a folder with ``Repetition count_<class>`` in the regularization image folder. Please prepare multiple
|
||||
|
||||
For example, learning "sls frog" and "cpc rabbit" at the same time would look like this:
|
||||
|
||||

|
||||
|
||||
If you have one class and multiple targets, you can have only one regularized image folder. For example, if 1girl has character A and character B, do as follows.
|
||||
|
||||
- train_girls
|
||||
- 10_sls 1girl
|
||||
- 10_cpc 1girl
|
||||
- reg_girls
|
||||
-1_1girl
|
||||
|
||||
If the number of data varies, it seems that good results can be obtained by adjusting the number of repetitions to unify the number of sheets for each class and identifier.
|
||||
|
||||
## Use captions in DreamBooth
|
||||
If you put a file with the same file name as the image and the extension .caption (you can change it in the option) in the training image and regularization image folders, the caption will be read from that file and learned as a prompt.
|
||||
|
||||
* The folder name (identifier class) will no longer be used for training those images.
|
||||
|
||||
Adding captions to each image (you can use BLIP, etc.) may help clarify the attributes you want to learn.
|
||||
|
||||
Caption files have a .caption extension by default. You can change it with --caption_extension. With the --shuffle_caption option, study captions during learning while shuffling each part separated by commas.
|
||||
1221
train_network.py
1221
train_network.py
File diff suppressed because it is too large
Load Diff
@ -186,4 +186,4 @@ Text Encoderが二つのモデルで同じ場合にはLoRAはU-NetのみのLoRA
|
||||
|
||||
### 将来拡張について
|
||||
|
||||
LoRAだけでなく他の拡張にも対応可能ですので、それらも追加予定です。
|
||||
LoRAだけでなく他の拡張にも対応可能ですので、それらも追加予定です。
|
||||
@ -1,35 +1,32 @@
|
||||
# Train network documentation translated from japanese
|
||||
## About learning LoRA
|
||||
|
||||
[LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) (arxiv), [LoRA](https://github.com/microsoft/LoRA) (github) to Stable Applied to Diffusion.
|
||||
|
||||
[cloneofsimo's repository](https://github.com/cloneofsimo/lora) was a great reference. thank you.
|
||||
[cloneofsimo's repository](https://github.com/cloneofsimo/lora) was a great reference. Thank you very much.
|
||||
|
||||
8GB VRAM seems to work just fine.
|
||||
|
||||
## A Note about Trained Models
|
||||
|
||||
Cloneofsimo's repository and d8ahazard's [Drebooth Extension for Stable-Diffusion-WebUI](https://github.com/d8ahazard/sd_drebooth_extension) are currently incompatible due to ongoing enhancements (see below).
|
||||
Cloneofsimo's repository and d8ahazard's [Drebooth Extension for Stable-Diffusion-WebUI](https://github.com/d8ahazard/sd_drebooth_extension) are currently incompatible. Because we are doing some enhancements (see below).
|
||||
|
||||
In order to generate images using WebUI, it is necessary to merge the learned LoRA model with the Stable Diffusion model using the script in this repository. The resulting merged model file will incorporate the learning results from LoRA. Note that merging is not required when generating images with the script in this repository.
|
||||
|
||||
Note that merging is not required when generating with the image generation script in this repository.
|
||||
When generating images with WebUI, etc., merge the learned LoRA model with the learning source Stable Diffusion model in advance with the script in this repository, or click here [Extention for WebUI] (https://github .com/kohya-ss/sd-webui-additional-networks).
|
||||
|
||||
## Learning method
|
||||
|
||||
Use train_network.py.
|
||||
|
||||
You can learn both the DreamBooth method (using identifiers (sks, etc.) and classes, optionally with regularized images) and the fine tuning method using captions.
|
||||
You can learn both the DreamBooth method (using identifiers (sks, etc.) and classes, optionally regularized images) and the fine tuning method using captions.
|
||||
|
||||
Both methods can be learned in much the same way as existing scripts. We will discuss the differences later.
|
||||
|
||||
### Using the DreamBooth Method
|
||||
|
||||
Please refer to note.com [Environment preparation and DreamBooth learning script](https://note.com/kohya_ss/n/nba4eceaa4594) to prepare the data.
|
||||
Please refer to [DreamBooth guide](./train_db_README-en.md) and prepare the data.
|
||||
|
||||
Specify train_network.py instead of train_db.py when training.
|
||||
|
||||
Almost all options are available (except model saving related to Stable Diffusion), but stop_text_encoder_training is not supported.
|
||||
Almost all options are available (except Stable Diffusion model save related), but stop_text_encoder_training is not supported.
|
||||
|
||||
### When to use captions
|
||||
|
||||
@ -75,7 +72,9 @@ In addition, the following options can be specified.
|
||||
* --text_encoder_lr
|
||||
* Specify when using a learning rate different from the normal learning rate (specified with the --learning_rate option) for the LoRA module associated with the Text Encoder. Some people say that it is better to set the Text Encoder to a slightly lower learning rate (such as 5e-5).
|
||||
|
||||
If both --network_train_unet_only and --network_train_text_encoder_only are not specified (default), both Text Encoder and U-Net LoRA modules will be enabled. ## About the merge script
|
||||
When neither --network_train_unet_only nor --network_train_text_encoder_only is specified (default), both Text Encoder and U-Net LoRA modules are enabled.
|
||||
|
||||
## About the merge script
|
||||
|
||||
merge_lora.py allows you to merge LoRA training results into a Stable Diffusion model, or merge multiple LoRA models.
|
||||
|
||||
@ -109,7 +108,7 @@ python networks\merge_lora.py --sd_model ..\model\model.ckpt
|
||||
|
||||
### Merge multiple LoRA models
|
||||
|
||||
After all, it may not be very useful because it cannot be inferred unless it is merged into the SD model. However, when merging multiple LoRA models one by one into the SD model, and when merging multiple LoRA models and then merging them into the SD model, the result will be slightly different in relation to the calculation order.
|
||||
Applying multiple LoRA models one by one to the SD model and merging multiple LoRA models and then merging them into the SD model yield slightly different results in relation to the calculation order.
|
||||
|
||||
For example, a command line like:
|
||||
|
||||
@ -143,14 +142,48 @@ Add options --network_module, --network_weights, --network_dim (optional) to gen
|
||||
|
||||
You can change the LoRA application rate by specifying a value between 0 and 1.0 with the --network_mul option.
|
||||
|
||||
## Create a LoRA model from the difference between two models
|
||||
|
||||
It was implemented with reference to [this discussion](https://github.com/cloneofsimo/lora/discussions/56). I used the formula as it is (I don't understand it well, but it seems that singular value decomposition is used for approximation).
|
||||
|
||||
LoRA approximates the difference between two models (for example, the original model after fine tuning and the model after fine tuning).
|
||||
|
||||
### How to run scripts
|
||||
|
||||
Please specify as follows.
|
||||
```
|
||||
python networks\extract_lora_from_models.py --model_org base-model.ckpt
|
||||
--model_tuned fine-tuned-model.ckpt
|
||||
--save_to lora-weights.safetensors --dim 4
|
||||
```
|
||||
|
||||
Specify the original Stable Diffusion model for the --model_org option. When applying the created LoRA model, this model will be specified and applied. .ckpt or .safetensors can be specified.
|
||||
|
||||
Specify the Stable Diffusion model to extract the difference in the --model_tuned option. For example, specify a model after fine tuning or DreamBooth. .ckpt or .safetensors can be specified.
|
||||
|
||||
Specify the save destination of the LoRA model in --save_to. Specify the number of dimensions of LoRA in --dim.
|
||||
|
||||
A generated LoRA model can be used in the same way as a trained LoRA model.
|
||||
|
||||
If the Text Encoder is the same for both models, LoRA will be U-Net only LoRA.
|
||||
|
||||
### Other Options
|
||||
|
||||
--v2
|
||||
- Please specify when using the v2.x Stable Diffusion model.
|
||||
--device
|
||||
- If cuda is specified as ``--device cuda``, the calculation will be performed on the GPU. Processing will be faster (because even the CPU is not that slow, it seems to be at most twice or several times faster).
|
||||
--save_precision
|
||||
- Specify the LoRA save format from "float", "fp16", "bf16". Default is float.
|
||||
|
||||
## Additional Information
|
||||
|
||||
### Differences from cloneofsimo's repository
|
||||
|
||||
As of 12/25, this repository has expanded LoRA application points to Text Encoder's MLP, U-Net's FFN, and Transformer's in/out projection, increasing its expressiveness. However, the amount of memory used increased, and it became the last minute of 8GB instead.
|
||||
As of 12/25, this repository has expanded LoRA application points to Text Encoder's MLP, U-Net's FFN, and Transformer's in/out projection, increasing its expressiveness. However, the amount of memory used increased instead, and it became the last minute of 8GB.
|
||||
|
||||
Also, the module replacement mechanism is completely different.
|
||||
|
||||
### About future expansion
|
||||
### About Future Expansion
|
||||
|
||||
It is possible to support not only LoRA but also other expansions, so we plan to add them as well.
|
||||
3
upgrade.ps1
Normal file
3
upgrade.ps1
Normal file
@ -0,0 +1,3 @@
|
||||
git pull
|
||||
.\venv\Scripts\activate
|
||||
pip install --upgrade -r requirements.txt
|
||||
Loading…
Reference in New Issue
Block a user